La sécurité du cloud n'est pas nouvelle. En fait, elle existe depuis un bon nombre d'années maintenant.
Cependant, chaque année qui passe, le cloud devient plus complexe, et avec cette complexité viennent de nouveaux risques.
Il y a dix ans, le cloud ne concernait que le stockage et le calcul. Mais aujourd'hui, les API, les identités, les charges de travail IA et des entreprises entières sont construites dans le cloud. Cela montre simplement que la surface d'attaque ne cesse de croître.
Pourtant, malgré cela, de nombreuses organisations traitent encore la sécurité du cloud comme une checklist. Cela se résume à : Chiffrez ceci. Ajoutez la MFA. Exécutez un scan de temps en temps.
Alors qu'en réalité, vous savez, comme moi, qu'il suffit d'une seule mauvaise configuration pour qu'elle passe inaperçue. D'une prolifération des permissions. D'une instance de shadow IT qui s'insinue. Et c'est tout ce dont un attaquant a besoin pour trouver une faille.
Une façon de vous assurer de ne pas tomber dans ce piège est de suivre les bonnes pratiques de sécurité du cloud. Non pas comme un cliché, mais comme une approche fondamentale pour construire et maintenir un environnement cloud sécurisé.
Dans cet article, vous découvrirez 25 bonnes pratiques de sécurité du cloud que chaque organisation devrait suivre pour vous aider à anticiper les menaces et à protéger vos données, applications et utilisateurs.
Mais d'abord, comprenons pourquoi la sécurité du cloud est à la fois importante et complexe.
Pourquoi la sécurité du cloud est-elle importante et complexe ?
Le passage du sur site au cloud a tout changé. Soudain, les équipes pouvaient obtenir le matériel dont elles avaient besoin en quelques minutes au lieu de mois, et avec presque aucun coût initial. Bien que cette vitesse ait libéré l'innovation, elle a également ouvert la voie à de nouveaux risques.
À l'époque du sur site, les équipes de sécurité avaient un contrôle strict sur les serveurs physiques, les réseaux et l'accès. Dans le cloud, cependant, ce contrôle est partagé.
Les ingénieurs peuvent déployer des ressources en quelques clics, et les charges de travail s'exécutent sur différentes régions, comptes et même fournisseurs. Ce type de démocratisation est puissant, mais cela signifie également que la surface d'attaque est plus vaste que jamais. Et rappelez-vous : la sécurité du cloud repose sur le modèle de responsabilité partagée.
Le véritable défi découle de deux éléments : l'échelle et la complexité. Vous ne sécurisez plus un environnement fixe. À grande échelle, vous sécurisez des centaines de conteneurs éphémères, de fonctions serverless et de services, qui se lancent et s'arrêtent à la minute.
Maintenant, si vous ajoutez les exigences de conformité, les configurations multi-cloud et la pression constante pour livrer plus rapidement, il n'est pas difficile de comprendre pourquoi la sécurité du cloud est à la fois cruciale et difficile à maîtriser.
Gouvernance et Bonnes Pratiques en Matière de Sécurité du cloud
En matière de sécurité du cloud, la confusion est l'un de vos plus grands ennemis. Si personne ne sait qui est responsable de quoi, des lacunes commencent à apparaître. C'est pourquoi la gouvernance et la responsabilité sont les premières bonnes pratiques à maîtriser.
1. Comprendre le modèle de responsabilité partagée au-delà du fournisseur de cloud
Le modèle de responsabilité partagée n'est pas universel ; il dépend du type d'environnement cloud que vous utilisez. Par exemple, une organisation utilisant une infrastructure IaaS a bien plus de responsabilités qu'une startup d'IA de six mois basée sur du FaaS.
L'image ci-dessous, fournie par le Center for Internet Security (CIS), illustre le niveau de responsabilité d'un client cloud.

Au-delà de l'image ci-dessus, il est important de se rappeler que les incidents de sécurité ne se produisent pas de manière isolée. Ce qui signifie que la sécurité du cloud n'est pas seulement « le travail de l'équipe de sécurité ». C'est un effort collectif impliquant l'ingénierie, les opérations et la direction.
Dans cette optique, comment adopter ce modèle de responsabilité partagée sans que cela ne se transforme en jeu de reproches ?
La réponse est... roulements de tambour... « Shift Left ».
Peut-être l'aviez-vous deviné, peut-être pas. Quoi qu'il en soit, le « Shift Left » est plus qu'un simple mot à la mode. Le code écrit par les développeurs, l'infrastructure et tout ce qui se trouve entre les deux sont autant de vecteurs d'attaque potentiels et ne font aucune différence pour un acteur malveillant.
Ainsi, au lieu de ne vous soucier de la sécurité qu'en temps d'exécution, vous devriez commencer à vous en préoccuper dès la première ligne de code.
Dans l'éventualité où des incidents se produiraient à n'importe quelle étape du cycle de vie du développement logiciel (SDLC), l'idée de post-mortem sans reproche des SRE s'avère utile pour tirer des leçons de cet échec.
Bonnes pratiques à adopter :
- Apprenez les responsabilités spécifiques de votre fournisseur de cloud et comprenez ce qui vous incombe dans votre type d'environnement cloud.
- Intégrez la sécurité en amont en équipant les développeurs d'outils de sécurité axés sur les développeurs qui s'intègrent directement dans leur flux de travail, protégeant contre les anti-patterns, les dépendances vulnérables et les secrets codés en dur qui se glissent dans les systèmes de contrôle de version.
- Utilisez l'idée des post-mortems sans reproche pour tirer des leçons des incidents sans désigner de coupables.
- Appliquez des garde-fous avec des outils Policy-as-Code. Ne vous inquiétez pas, nous aborderons ces recommandations plus en détail plus loin dans cet article.
2. Intégrer la Sécurité aux Exigences de Conformité
On ne peut pas parler de gouvernance sans sa compatriote : la conformité. Les deux vont de pair. La gouvernance établit les règles du jeu, et la conformité s'assure que vous les respectez.
Mais le problème est que de nombreuses organisations traitent la conformité comme un simple exercice administratif. Peut-être la vôtre aussi.
Réussir l'audit, obtenir le badge, et passer à autre chose.
Cet état d'esprit est dangereux. Les cadres de conformité comme le RGPD ou le PCI DSS ne sont pas de simples obstacles à franchir ; ce sont des garde-fous conçus pour protéger les données sensibles et réduire les risques. Lorsqu'ils sont bien mis en œuvre, ils améliorent votre posture de sécurité de base. Lorsqu'ils sont mal faits, c'est un effort gâché.
Bonnes pratiques à adopter :
La clé est d'intégrer la conformité dans les flux de travail quotidiens. En utilisant les mêmes outils que vous utilisez déjà pour sécuriser votre infrastructure. Certaines solutions vous aident en automatisant les contrôles de sécurité du code et du cloud pour ISO 27001, SOC 2 Type 2, PCI, DORA, NIS2, HIPAA et plus encore.
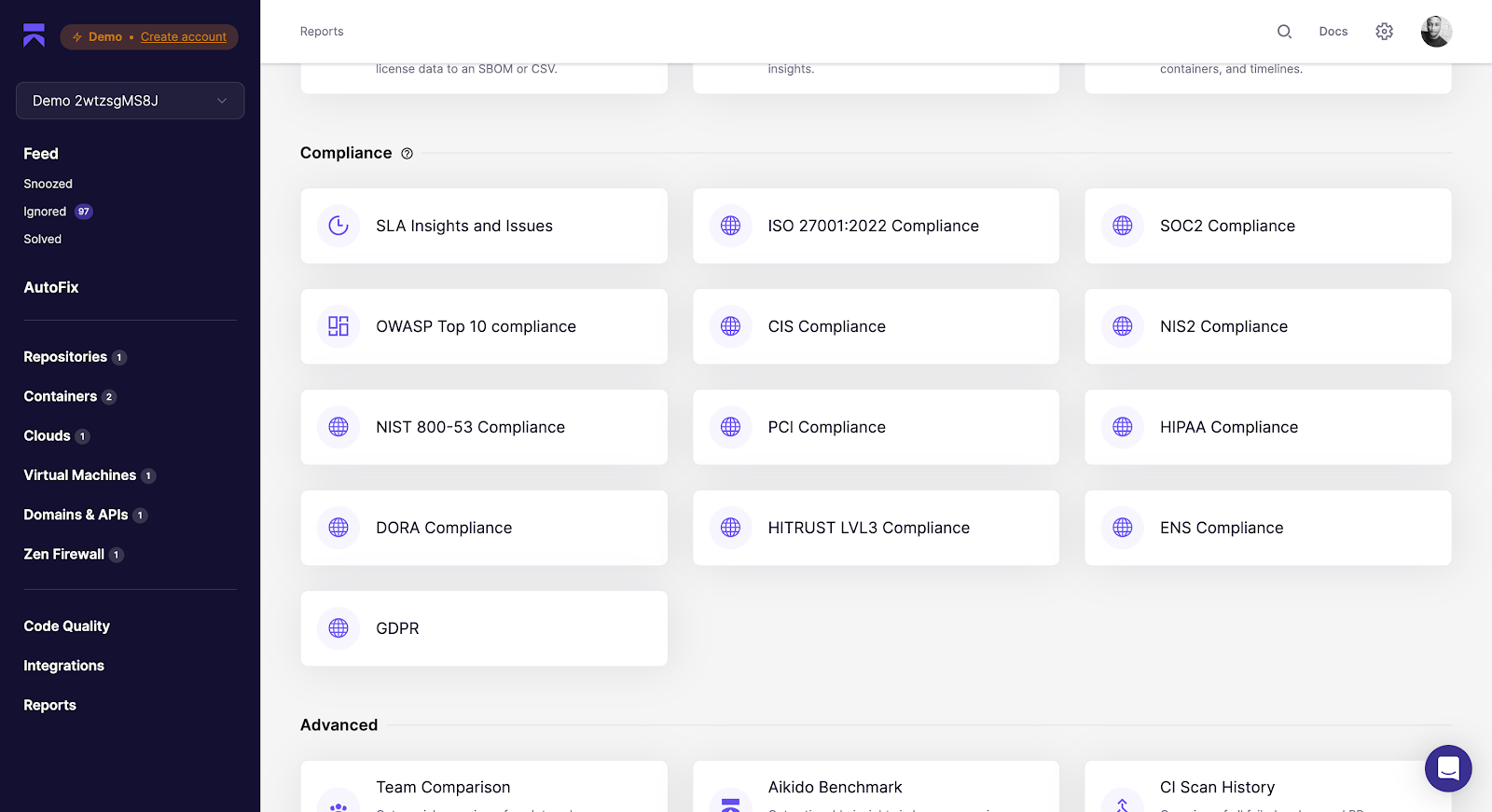
Bonnes Pratiques en Matière de Gestion des Identités et des Accès pour la Sécurité du cloud
Maintenant que toutes les bonnes pratiques de gouvernance ont été abordées, passons à l'un des aspects les plus complexes de la sécurité du cloud : la gestion des identités et des accès.
3. Appliquer le Principe du moindre privilège
La première étape pour gérer efficacement l'accès aux identités consiste à s'assurer que chaque identité dispose de l'accès dont elle a besoin, et rien de plus. C'est ce qu'encourage le Principe du moindre privilège (PoLP).
Il est important de noter que le PoLP devrait également s'appliquer aux identités non humaines telles que les API, les comptes de service, les conteneurs, les fonctions serverless, etc., qui fonctionnent souvent avec des permissions trop larges par commodité.
En cas de compromission, ces permissions peuvent être exploitées aussi facilement qu'un compte administrateur humain. En appliquant le PoLP aux humains et aux workloads, vous réduisez le rayon d'impact de toute violation potentielle.
Bonnes pratiques à adopter :
- Adopter une politique de « tout refuser » par défaut, puis n'accorder que les actions minimales requises.
- Remplacer les jokers (s3:*) par des actions explicites (par exemple, s3:GetObject, s3:PutObject).
- Auditer régulièrement et supprimer les permissions inutilisées des rôles IAM et des comptes de service. Par exemple, au lieu de donner à une fonction Lambda l'accès AmazonS3FullAccess, attacher une politique IAM personnalisée telle que :
{
"Version": "2012-10-17",
"Statement": [
{ "Effect": "Allow",
"Action": ["s3:GetObject", "s3:PutObject"],
"Resource": "arn:aws:s3:::my-app-bucket/*"
}
]
}Cela garantit que la fonction ne peut lire et écrire que dans le seul bucket dont elle a réellement besoin, et rien d'autre.
4. Utiliser l'authentification multi-facteurs (MFA)
Même si chaque identité ne dispose que des accès nécessaires, il est toujours important de mettre en œuvre l'authentification multi-facteurs, en particulier pour les comptes administrateurs et critiques. La MFA ajoute une seconde couche de protection au-delà des identifiants.
La plupart des authentifications multi-facteurs utilisent aujourd'hui l'authentification par e-mail. Bien que cela ajoute une couche de sécurité supplémentaire comme prévu, elles sont facilement sujettes au phishing.
Bonnes pratiques à adopter :
- Lors de la mise en œuvre de la MFA, vous devriez choisir des options qui protègent contre le phishing et d'autres cyberattaques, comme les YubiKeys. Ces solutions offrent une MFA basée sur une clé physique, ce qui exigerait qu'un attaquant vole physiquement la clé.
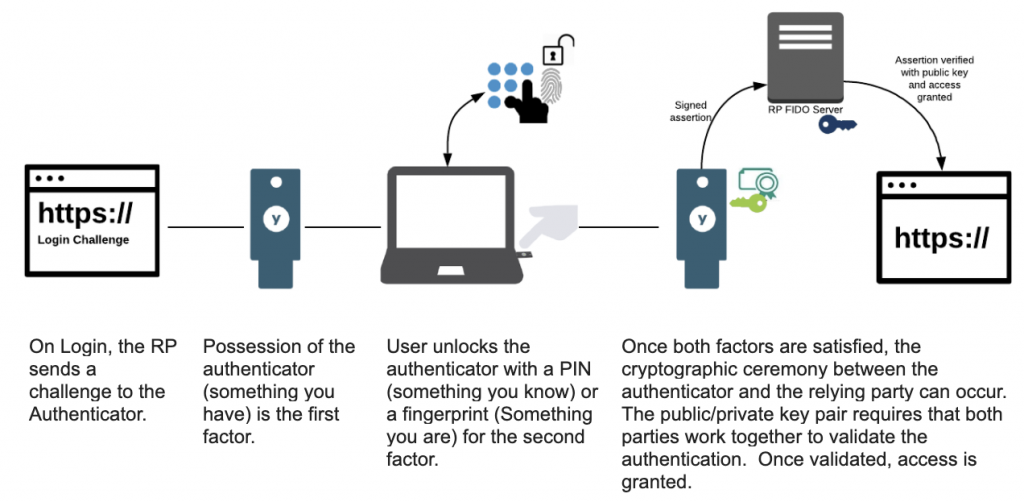
- Intégrer les clés matérielles avec votre fournisseur SSO (Okta, Azure AD, Google Workspace) pour une adoption fluide.
- Exiger l'authentification multi-facteurs pour les actions à haut risque (par exemple, l'accès à l'environnement de production, la modification des politiques IAM).
- Auditer régulièrement l'enregistrement MFA pour s'assurer que tous les comptes (y compris ceux des sous-traitants) sont couverts et modifiés en fonction de l'évolution du contexte métier.
5. Aller au-delà du RBAC avec des politiques
Le RBAC et les outils IAM classiques ne suffisent pas à résoudre les défis liés à la gestion des identités dans les environnements cloud-native, que ce soit au niveau du cloud, du cluster, du conteneur ou du code, en particulier pour les identités non humaines comme les comptes de service, les clés API, les certificats et les secrets.
Les bonnes pratiques de sécurité cloud-native exigent l'utilisation de la Politique en tant que Code (PaC) pour appliquer des permissions dynamiques et granulaires adaptées à des scénarios spécifiques.
Ensemble, ils créent une stratégie d'accès en couches :
- RBAC définit le qui et le quoi.
- PaC définit le quand, le comment et dans quelles conditions spécifiques.
Par exemple, un ingénieur ayant le rôle d'administrateur de plateforme (RBAC) peut déployer en staging. Cependant, une règle PaC bloque le déploiement si l'image n'est pas scannée, si la branche n'est pas signée ou si l'opération a lieu en dehors des heures ouvrables.
Cette combinaison applique le principe du moindre privilège à grande échelle, prévient les erreurs et rend la sécurité reproductible, testable et auditable.
Bonnes pratiques à adopter :
Si vous utilisez le cloud AWS, son écosystème fournit des outils pour une implémentation proactive, préventive, détective et réactive des politiques. Nous vous recommandons de lire ce guide pratique pour démarrer avec le Policy as Code sur AWS.
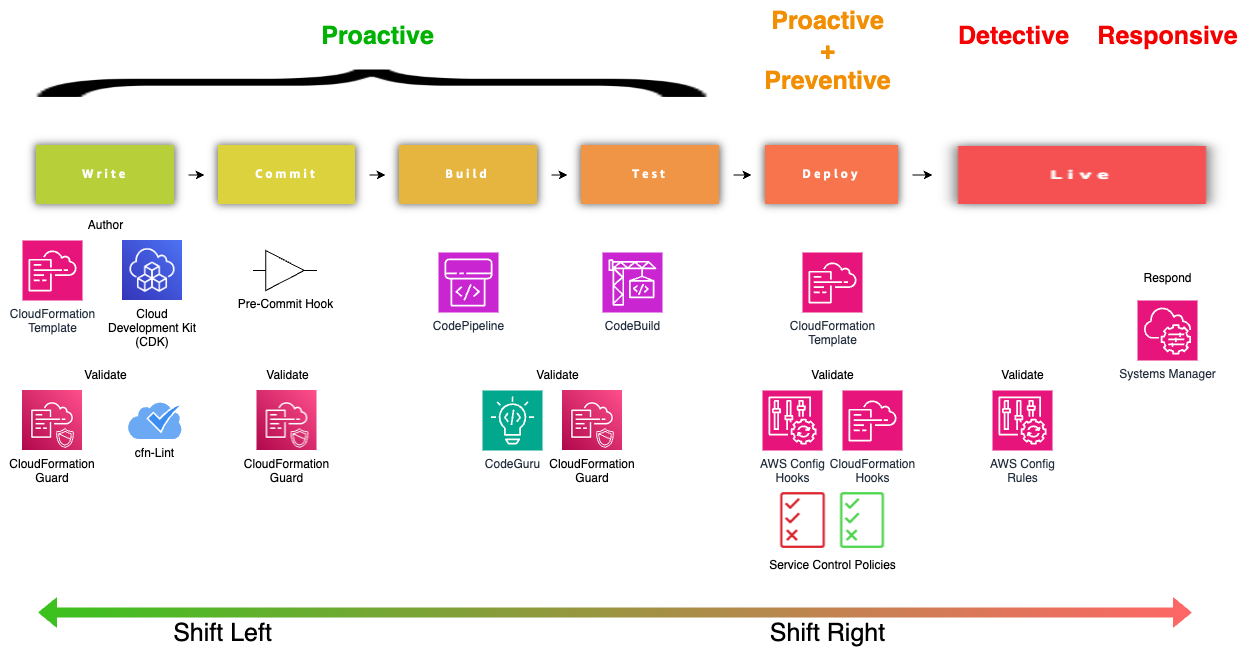
D'autres fournisseurs de services cloud comme Azure proposent également des outils de Policy as Code. Vous pouvez également envisager des outils PaC open source tels que Open Policy Agent (OPA) et Kyverno, qui sont agnostiques en matière de plateforme et « cloud-native » par défaut.
6. Rotation régulière des clés et des identifiants
Les gens attendent qu'il y ait une effraction avant de changer les clés. Vous ne devriez pas. Vous devriez faire pivoter automatiquement les clés régulièrement.
À quelle fréquence est « régulièrement » ? Mensuellement, trimestriellement ou annuellement ? Le CIS AWS Foundations Benchmark recommande tous les 90 jours ou moins.
Dans les environnements complexes, moins, c'est plus en matière de rotation des clés, surtout pour les identités non humaines. L'automatisation plus fréquente de ces clés réduit considérablement le risque de brèche si une clé est compromise car, dans la plupart des cas, ces types d'identités ont peu ou pas de visibilité.
Bonnes pratiques à adopter :
- Remplacez les identifiants statiques par des jetons de courte durée (par exemple, AWS STS, GCP Workload Identity, Azure Managed Identities).
- Stockez et faites pivoter les secrets à l'aide d'un gestionnaire centralisé (AWS Secrets Manager, HashiCorp Vault, Azure Key Vault) au lieu de les intégrer dans le code ou les fichiers de configuration.
- Surveillez les logs (CloudTrail, Audit Logs, Azure Monitor) pour détecter toute utilisation inhabituelle des identifiants après leur rotation.
- Auditez les clés inutilisées et exposées et révoquez-les immédiatement. Les outils de détection de secrets en temps réel vous aident à trouver tous les secrets actifs et leurs risques potentiels.
7. Tirez parti de l'accès Just-in-Time (JIT)
Il arrive qu'un utilisateur cloud avec un accès minimal ait besoin de privilèges élevés pour accomplir sa tâche. Au lieu d'élever l'accès par défaut de cet utilisateur, vous devriez implémenter un accès Just-in-Time (JIT) pour accorder une élévation temporaire des privilèges au lieu de permissions permanentes.
Bonnes pratiques à adopter :
- Un développeur demandera un rôle avec les privilèges dont il a besoin, avec :
- Okta Access Requests et AWS IAM Identity Center sur AWS
- Accès machine Just-in-time sur Azure
- Privileged Access Manager sur Google Cloud ou d'autres outils externes
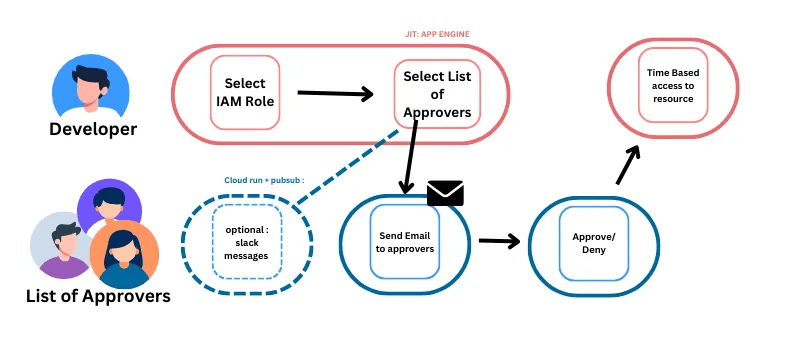
- Fixez toujours des limites de temps (par exemple, 30 minutes, 1 heure, 1 jour) pour les sessions à privilèges élevés ; pas d'approbations illimitées.
- Exigez une réauthentification MFA avant d'accorder l'accès JIT.
- Journalisez et surveillez toutes les requêtes et approbations JIT pour l'auditabilité.
Bonnes pratiques de protection des données et de sécurité du cloud
Les données sont le moteur de toute entreprise. En fait, si l'on vous demandait de choisir entre une violation de vos serveurs ou une violation de votre base de données, vous choisiriez vos serveurs sans hésiter. C'est dire à quel point vos données sont précieuses pour vous.
Alors, comment sécuriser vos données dans le cloud ?
8. Chiffrer les données en transit et au repos
Que ce soit en stockage ou en transit, vous devez chiffrer vos données cloud. Au repos, utilisez des algorithmes de chiffrement robustes et modernes comme AES-256 ou TDE (Transparent Data Encryption). Cela garantit que même si un attaquant accède au stockage sous-jacent, les données restent illisibles sans les clés de chiffrement nécessaires.
Pour les données en transit, toutes les communications, y compris les appels API et le trafic inter-services, doivent être sécurisées à l'aide de protocoles tels que TLS/SSL. Dans un environnement zero-trust, vous devez implémenter le TLS mutuel (mTLS), car il garantit que les charges de travail/identités à chaque extrémité d'une connexion réseau sont bien celles qu'elles prétendent être en vérifiant qu'elles possèdent toutes deux la clé privée correcte.
Le chiffrement des données cloud repose sur un système de gestion de clés (KMS) robuste. Votre KMS doit être un service sécurisé et centralisé pour la génération, le stockage, la gestion et la rotation des clés de chiffrement.
Bonnes pratiques à adopter :
- Chiffrer tous les volumes de stockage, bases de données et stockages d'objets (par exemple, AWS S3 SSE, Azure Storage Service Encryption, GCP CMEK).
- Appliquez TLS 1.2+ pour tous les points de terminaison API et le trafic inter-services.
- Implémentez le mTLS pour les microservices internes afin d'éviter l'usurpation d'identité.
- Centralisez la gestion des clés avec un KMS géré (AWS KMS, Azure Key Vault, GCP KMS, HashiCorp Vault).
- Automatiser la rotation des clés et surveiller l'utilisation non autorisée des clés.
L'extrait de Kubernetes Ingress ci-dessous impose le mTLS en exigeant des clients qu'ils présentent un certificat valide d'une CA de confiance (client-ca) avant de pouvoir accéder au service.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: app-ingress-mtls
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/auth-tls-secret: "prod/client-ca" # client CA cert
nginx.ingress.kubernetes.io/auth-tls-verify-client: "on" # require client cert
spec:
tls:
- hosts:
- secure.example.com
secretName: secure-app-tls
rules:
- host: secure.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: app
port:
number: 80
9. Sauvegarder les Données et Tester la Récupération
Il existe principalement deux règles d'or pour la sauvegarde des données : la règle 3-2-1 et la règle 3-2-1-1-0.
La règle 3-2-1 recommande :
- 3 = Maintenez Trois Copies de Vos Données
- 2 = Utilisez Deux Types de Supports de Stockage Différents
- 1 = Stockez Une Copie Hors Site
La règle 3-2-1-1-0 s'appuie sur la 3-2-1 pour protéger contre les menaces modernes et vous recommande de :
- 3 = Maintenez Trois Copies de Vos Données
- 2 = Utilisez Deux Types de Supports de Stockage Différents
- 1 = Stockez Une Copie Hors Site
- 1 = Stockez Une Copie Hors Ligne ou Immuable
- 0 = Assurez Zéro Erreur de Sauvegarde
La question principale n'est pas de savoir si vous effectuez des sauvegardes, mais si vous pouvez récupérer avec ces sauvegardes. De nombreuses équipes supposent que les sauvegardes sont sûres jusqu'à ce qu'une catastrophe survienne, pour découvrir ensuite des fichiers corrompus, des données manquantes ou des processus de récupération qui prennent des jours au lieu d'heures.
Tester les sauvegardes peut sembler superflu lorsque tout fonctionne sans accroc, mais les pannes ne surviennent pas selon un calendrier préétabli.
Imaginez la différence de rétablissement entre une sauvegarde testée et une sauvegarde non testée lors d'une panne majeure.
Bonnes pratiques à adopter :
- Chiffrez les sauvegardes au repos et en transit.
- Effectuez régulièrement des exercices de récupération pour établir et valider les objectifs de point de récupération (RPO) et les objectifs de temps de récupération (RTO).

- Documentez les procédures de récupération afin qu'elles puissent être exécutées sous pression.
- Faites pivoter et nettoyez les anciennes sauvegardes pour réduire la surface d'attaque et les coûts.
Vous êtes prêt !!
10. Classer et étiqueter les données sensibles
Vous ne pouvez pas protéger ce que vous ignorez posséder. Dans la plupart des environnements cloud, les données sensibles sont réparties entre les buckets S3, les bases de données, les files d'attente de messages et même les journaux. Sans une classification appropriée, il est impossible d'appliquer les contrôles adéquats.
En étiquetant et en classifiant les données en fonction de leur sensibilité—publique, interne, confidentielle, restreinte—vous créez de la visibilité et mettez en œuvre des garde-fous évolutifs.
De nombreux fournisseurs cloud prennent en charge des outils de classification intégrés (par exemple, AWS Macie, Azure Information Protection, GCP DLP). Une fois les données étiquetées, vous pouvez appliquer automatiquement le chiffrement, les restrictions d'accès et la surveillance.
Bonnes pratiques à adopter :
- Analysez les buckets de stockage et les bases de données pour les informations personnelles identifiables (PII), les identifiants et les données financières.
- Appliquez des balises ou des étiquettes de métadonnées (par exemple, sensibilité=confidentiel) pour déclencher des politiques.
- Automatisez la classification avec des outils cloud-native ou des scanners tiers.
- Restreignez l'accès aux classes de données « restreintes » uniquement aux rôles approuvés.
11. Appliquer la tokenisation et l'anonymisation
Parfois, protéger les données signifie les transformer de manière à les rendre inutilisables en cas de fuite. La tokenisation remplace les champs sensibles (comme les numéros de carte de crédit) par des substituts non sensibles, tandis que l'anonymisation supprime complètement les informations d'identification des ensembles de données. Ces deux approches réduisent l'exposition sans interrompre les flux de travail métier.
Ces techniques sont particulièrement critiques dans les environnements où les développeurs, les analystes ou les tiers ont besoin d'accéder à des ensembles de données sans voir les valeurs sensibles brutes. Correctement mises en œuvre, la tokenisation et l'anonymisation permettent d'équilibrer sécurité et convivialité.
Bonnes pratiques à adopter :
- Tokenisez les détails de paiement avant de les stocker. Vous pouvez utiliser un coffre-fort conforme PCI.
- Appliquez l'anonymisation pour les ensembles de données analytiques en masquant les informations personnelles identifiables (PII) (par exemple, noms, e-mails).
- Utilisez la tokenisation préservant le format afin que les systèmes continuent de valider les formats de données.
- Automatisez les transformations aux points d'ingestion pour garantir que les données brutes n'entrent jamais dans les journaux ou les systèmes non sécurisés.
Bonnes pratiques pour la sécurité du cloud, du réseau et de l'infrastructure
Pour bâtir des systèmes sécurisés et fiables, les organisations doivent renforcer les fondations de leurs environnements cloud. Cela implique l'adoption de bonnes pratiques pour la conception de réseau, la connectivité et la gestion d'infrastructure.
Voici comment procéder :
12. Mettre en œuvre la segmentation réseau
Les réseaux plats sont fragiles. Si chaque ressource de votre cloud se trouve sur le même réseau, une compromission d'une ressource donnera aux attaquants un champ libre sur l'ensemble de votre cloud. C'est pourquoi vous devriez mettre en œuvre la segmentation réseau pour votre stratégie de sécurité cloud.
Bonnes pratiques à adopter :
L'objectif est la microsegmentation. L'isolation des charges de travail en fonction de leur sensibilité et de leur fonction impose une approche zero-trust, où chaque connexion est traitée comme une menace potentielle. Vous pouvez y parvenir en utilisant des outils tels que les groupes de sécurité réseau, les VLAN privés et les pare-feu internes.
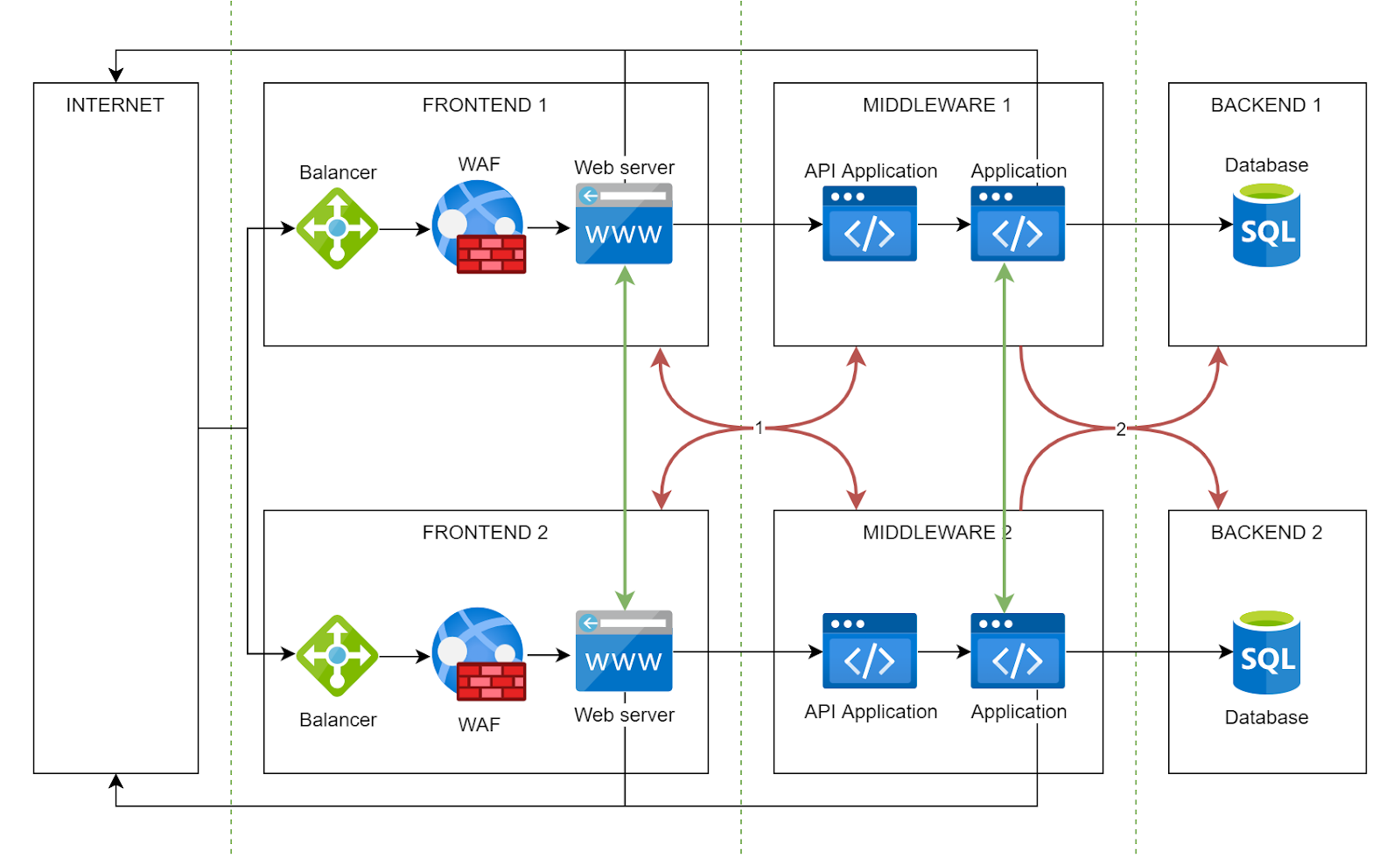
Dans l'illustration de segmentation réseau ci-dessus, il y a un accès internet dans les segments FRONTEND et MIDDLEWARE, mais l'accès entre les segments FRONTEND et MIDDLEWARE de différents systèmes d'information est interdit.
Cette couche fondamentale garantit que même si une mauvaise configuration ou une vulnérabilité est exploitée dans MIDDLEWARE 1, le rayon d'impact est minimal, protégeant ainsi les autres MIDDLEWARES.
13. Sécuriser les endpoints API
Les API sont le système nerveux des applications cloud. Et le moyen le plus rapide de tuer un organisme (les applications dans ce cas) est d'attaquer son système nerveux.
Il est prioritaire d'assurer que toutes les API de votre environnement disposent de mécanismes d'authentification et d'autorisation appropriés, afin que les acteurs de la menace ne puissent pas les exploiter pour obtenir un accès non autorisé ou perturber les services.
Bonnes pratiques à adopter :
- Placez toutes les API externes derrière une passerelle (Kong/Apigee/AWS API Gateway) avec des politiques par route.
- Exigez OAuth2/OIDC ; émettez des scopes de courte durée et à moindre privilège (pas de revendications génériques).
- Appliquez des limites de débit/quotas par clé API/client et des limites plus strictes sur les routes coûteuses.
- Activez TLS 1.2+ partout ; utilisez mTLS pour les appels de microservices internes.
- Découvrez et étiquetez automatiquement les API ; bloquez ou décommissionnez les versions non documentées et obsolètes.
- Envoyez les logs API à votre SIEM ; alertez sur les pics de 401/403, les extractions de données inhabituelles ou les modèles d'énumération.
- Et n'oubliez pas de scanner régulièrement vos API à la recherche de vulnérabilités et de failles.
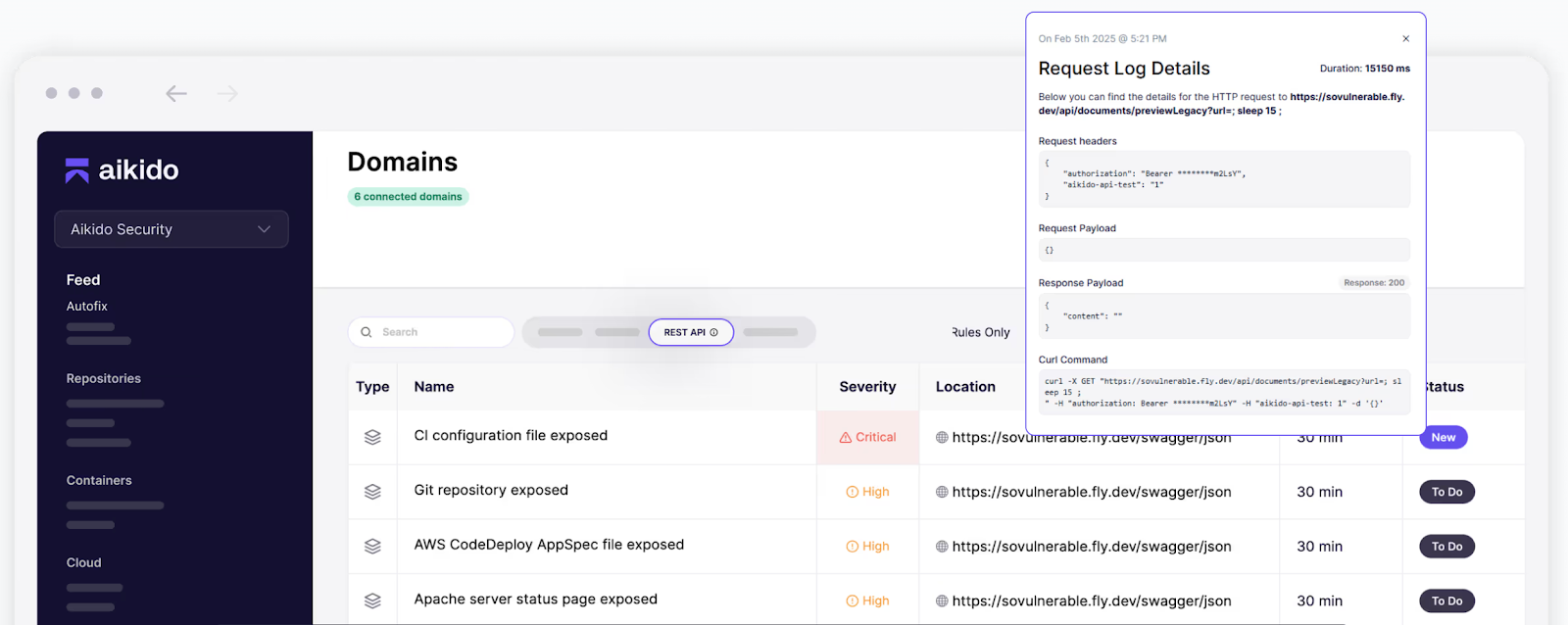
Comme mentionné, la sécurité des API est au cœur de votre stratégie de sécurité cloud. Pour plus de conseils et de tutoriels pratiques, consultez nos autres articles de blog :
- Tests de sécurité des API : Outils, listes de contrôle et évaluations
- Sécurité des API : Bonnes Pratiques et Normes
- Les meilleurs scanners d'API en 2025
- L'avenir de la sécurité des API : Tendances, IA et automatisation
14. Sécurité des conteneurs
Toute organisation souhaite profiter des avantages du cloud-native. Mais sont-elles également prêtes à relever ses défis ? Êtes-vous prêt ?
Les conteneurs sont la colonne vertébrale de l'infrastructure cloud-native, mais ils comportent également des risques uniques. Les erreurs de configuration, les images de base vulnérables et les privilèges excessifs peuvent tous ouvrir la porte aux attaquants.
Heureusement, la plupart des risques et problèmes liés à la sécurité des conteneurs peuvent être résolus en suivant les bonnes pratiques recommandées.
Bonnes pratiques à adopter :
- Utilisez toujours des images de base minimales et vérifiées (par exemple, distroless, Alpine) provenant de sources fiables. Utilisez des versions d'images spécifiques.
- Supprimez les capacités Linux inutiles (CAP_SYS_ADMIN est presque toujours un signal d'alarme).
- Ne jamais exécuter de conteneurs en tant que root ; si, dans un cas limite, un conteneur nécessite un accès root, remappez l'UID du conteneur vers un utilisateur moins privilégié sur l'hôte.
- Surveillez l'activité en temps d'exécution pour détecter et répondre aux comportements anormaux en temps réel.
- Analysez automatiquement les images et leurs dépôts pour trouver et corriger les vulnérabilités dans les paquets open source utilisés dans vos images de base et Dockerfiles.
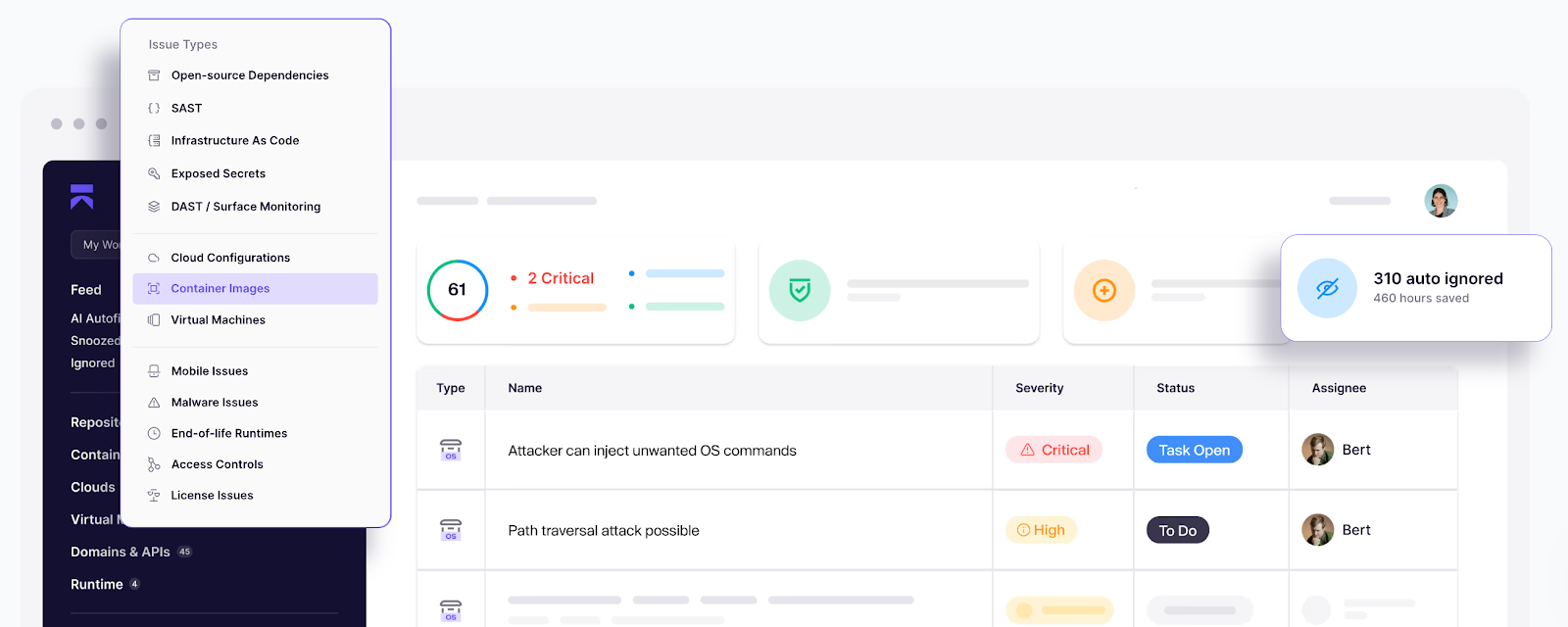
Si vous utilisez Kubernetes pour orchestrer vos conteneurs, vous pouvez configurer des contrôleurs d'admission pour intercepter les requêtes vers le serveur API, par exemple un déploiement, et valider que certaines conditions de sécurité sont remplies avant le déploiement.
15. Adoptez des bases de configuration sécurisées
Les paramètres par défaut sont conçus pour la commodité, pas pour la sécurité. Pour protéger votre infrastructure, sécurisez le système d'exploitation, le runtime des conteneurs et les services cloud avec des lignes de base prédéfinies afin de ne pas avoir à réinventer le durcissement à chaque sprint.
Bonnes pratiques à adopter :
- Partez des benchmarks CIS (OS spécifiques, Kubernetes, Docker, fournisseurs de cloud) et traitez-les comme du code : versionnés, révisés, appliqués via l'Infrastructure as Code (IaC).
- Appliquez les configurations avec la Policy-as-Code comme souligné précédemment (OPA, Kyrveno, Terraform Sentinel, Azure/AWS/GCP Policy).
- Activez les paramètres sécurisés par défaut : durcissement SSH, auditd, paramètres du noyau, conteneurs sans root, systèmes de fichiers en lecture seule.
Une fois tout cela configuré, détectez continuellement les erreurs de configuration, les expositions et les violations de politique sur tous vos clouds et corrigez-les rapidement.
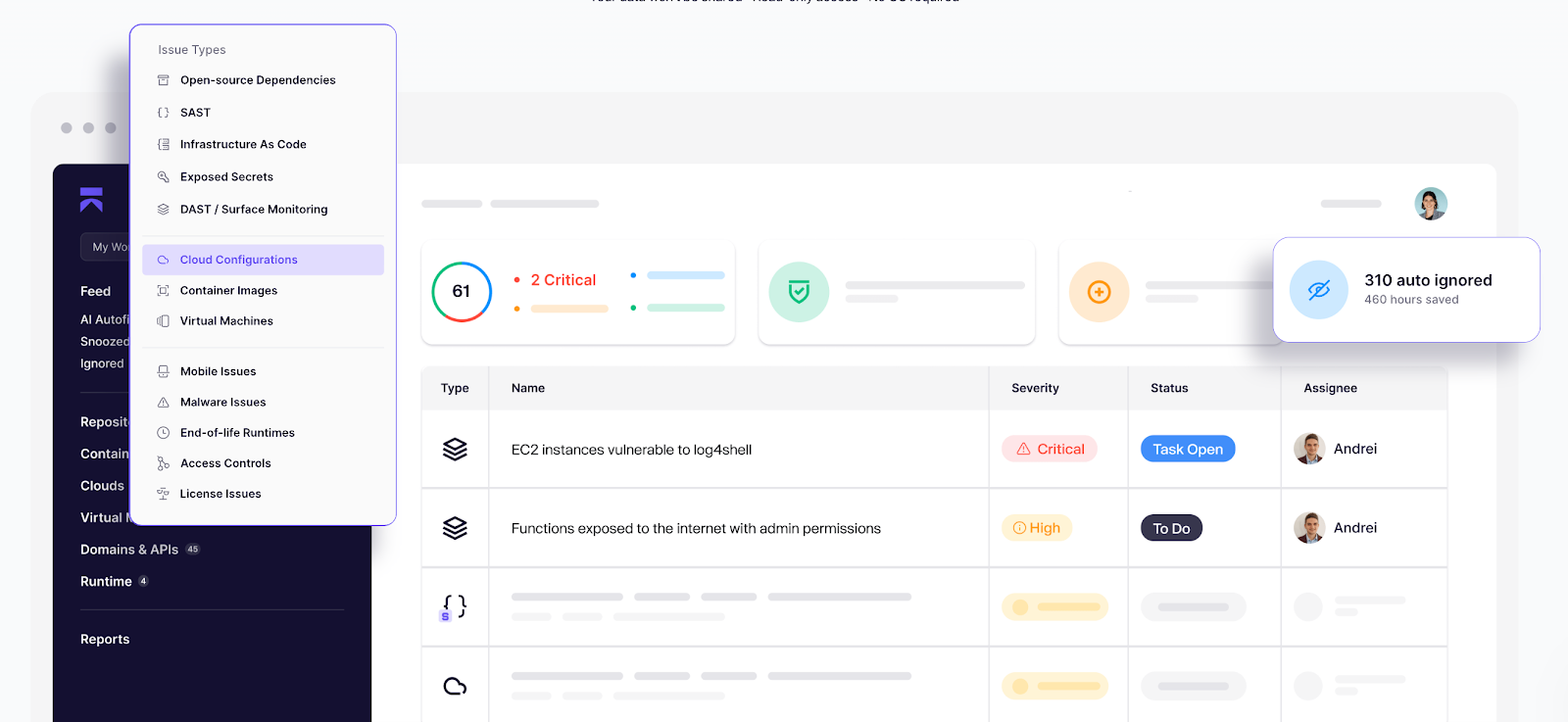
16. Appliquez régulièrement les mises à jour logicielles et les correctifs de sécurité
Soyons réalistes : non patché = vulnérable.
La recommandation générale est de vous assurer que chaque ressource de votre infrastructure est mise à jour vers une version stable et patchée.
Mais comment faire cela à grande échelle avec des centaines de services et d'outils ?
C'est là que l'IA avec un humain dans la boucle excelle pour obtenir une visibilité sur votre infrastructure et corriger automatiquement les problèmes.
Bonnes pratiques à adopter :
- Générez et suivez les SBOMs avec des outils capables de créer automatiquement des tickets pour les problèmes nécessitant votre intervention.
- Abonnez-vous aux flux CVE vérifiés par des chercheurs en sécurité pour rester informé des dernières menaces de la chaîne d'approvisionnement.
- Reconstruisez les images chaque semaine à partir d'images de base corrigées ; épinglez les digests, pas les tags.
- Utilisez des fenêtres de maintenance + des déploiements canary ; mesurez les taux d'erreur et revenez en arrière rapidement.
- Maintenez les services gérés sur des versions de moteur prises en charge (BDD, runtimes, passerelles).
17. Utilisez des pare-feu applicatifs (WAF) et la protection DDoS
Les WAF filtrent le trafic indésirable, et les protections DDoS vous maintiennent en ligne lorsque le trafic devient hostile. Placez-les devant les API/applications pour bloquer les injections SQL/XSS et limiter les attaques par inondation de couche 7, puis associez-les à des limites de débit et des contrôles de bots pour les abus plus subtils qui échappent aux signatures.
Si vous vous souvenez de l'illustration de segmentation réseau ci-dessus, un WAF est placé entre l'équilibreur de charge frontal et le serveur web.
Bonnes pratiques à adopter :
- Déployez un WAF (Aikido Zen/AWS WAF/Azure WAF/Cloud Armor) avec un ensemble de règles affiné (OWASP CRS + personnalisé).
- Activez la protection DDoS avec atténuation automatique.
- Inspectez les corps JSON (mode API), validez les schémas et enregistrez tous les blocages dans votre SIEM.
- Effectuez des exercices de chaos pour simuler des pics de charge et confirmer que les politiques d'autoscaling et de WAF/DDoS sont efficaces.
Détection des menaces et bonnes pratiques de surveillance pour la sécurité du cloud
Détecter et répondre rapidement aux menaces est essentiel pour réduire l'impact des incidents de sécurité dans le cloud, ce qui fait des bonnes pratiques de surveillance et de détection proactives un élément essentiel de la sécurité du cloud.
18. Mettez en œuvre des outils de surveillance et de journalisation avancés
Les logs sont votre système d'alerte précoce. Mais seulement si vous les centralisez et les analysez.
Dans le cloud, les événements se dispersent entre les services : appels d'API, activité des VM, logs d'audit Kubernetes, données de flux réseau.
Regroupez-les dans un SIEM ou un data lake, puis créez des tableaux de bord avec des outils de visualisation open source comme Grafana et des alertes afin que rien ne soit ignoré.
Bonnes pratiques à adopter :
- Activez la journalisation cloud-native avec des services tels que AWS CloudTrail, GuardDuty, VPC Flow Logs, Azure Monitor et GCP Cloud Audit Logs.
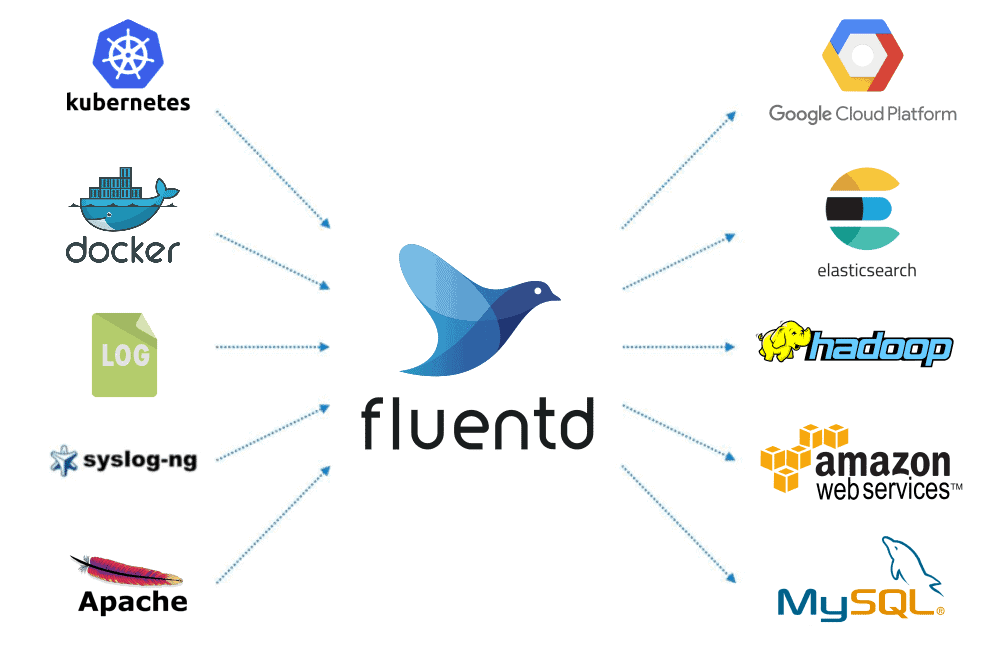
- Diffusez les logs vers un emplacement centralisé pour la corrélation. Vous pouvez et devriez utiliser un collecteur de données pour construire une couche de journalisation unifiée. L'un des plus robustes est Fluentd, qui est open source et dispose de plus de 500 plugins pour connecter des sources et des sorties de données tout en gardant son cœur simple.
- Une fois cela fait, définissez des alertes pour les actions à haut risque (modifications IAM, nouveaux buckets publics, escalades de privilèges).
- Définissez des politiques de rétention des logs qui répondent aux exigences de conformité et d'investigation forensique.
19. Utilisez un graphe de dépendances pour les évaluations des vulnérabilités
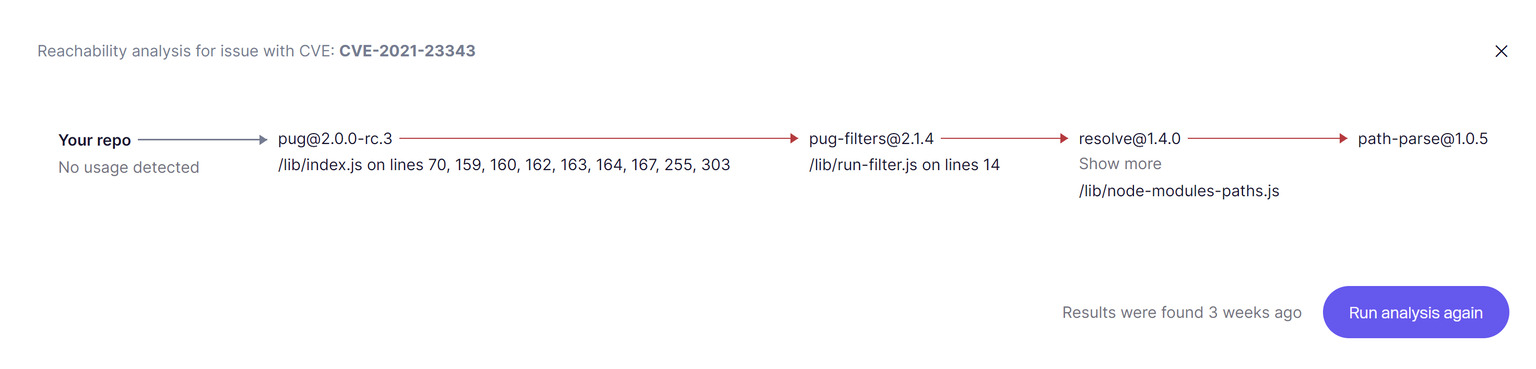
Depuis le début de ce guide, nous avons mentionné la découverte automatique des vulnérabilités. Il est également important de savoir que toutes les vulnérabilités ne méritent pas d'être corrigées. Ce qui compte, c'est de savoir lesquelles représentent réellement un risque dans votre environnement déployé.
C'est là qu'un graphe de dépendances devient essentiel. Sans lui, vous êtes aveugle, noyé sous des CVE sans importance, tout en manquant celles qui comptent vraiment.
Bonnes pratiques à adopter :
- Utilisez une plateforme qui offre une analyse d’accessibilité pour éliminer les fausses alertes et signaler uniquement les vulnérabilités exploitables.
- Ignorez les dépendances spécifiques au développement/test ; concentrez-vous sur ce qui est déployé en production.
- Priorisez les CVEs qui sont à la fois accessibles et exposées sur internet.
- Corrélez les vulnérabilités à travers le code, les conteneurs et les configurations cloud
20. Attention au Vibe Coding
Le Vibe Coding est la nouvelle tendance à la mode.
Les designers, les spécialistes du marketing, les commerciaux, ou n'importe qui peuvent désormais créer des applications ou des fonctionnalités sans avoir à écrire beaucoup de code eux-mêmes. Cela signifie souvent sans tests, sans révision, ni prise en compte de la sécurité. C'est rapide, sans friction et cela semble magique. Mais la magie sans garde-fous a tendance à se consumer.
Pour 'vibe coder' de manière plus sûre, les meilleures pratiques à adopter sont :
- Traitez le code généré par l'IA ou livré par des non-ingénieurs comme s'il avait été écrit par un développeur junior : faites toujours une code review. Faites-le examiner.
- Ne développez pas votre propre système d'authentification, de validation des entrées ou de gestion des secrets ; utilisez des bibliothèques ou des services bien examinés et audités.
- Gardez les secrets hors du frontend et des dépôts ; utilisez un stockage sécurisé et une gestion de l'environnement.
- Assurez-vous d'automatiser les scans (dépendances, SAST, DAST) sur les applications 'vibe-codées' avant le déploiement. Laissez les pipelines détecter les problèmes les plus évidents.
Vous voulez plus d'étapes pratiques ? Lisez notre liste de contrôle de sécurité pour les Vibe Coders.
21. Pentest continu dans le CI/CD
Le pentest continu bouleverse les vérifications de sécurité périodiques, en intégrant des tests automatisés dans votre pipeline de build et de déploiement afin que les vulnérabilités soient détectées avant qu'elles n'atteignent la production. Il s'agit de vitesse, de contexte et de boucles de rétroaction plus claires.
Bonnes pratiques à adopter :
- Mettez en place le SAST et l'analyse des secrets sur chaque pull request.
- Scans IaC dans votre CI (scannez les scripts Terraform, CloudFormation et Helm) avant le déploiement.
- Faites échouer les builds pour les vulnérabilités de gravité élevée/critique ; signalez les découvertes de gravité moyenne dans le tableau de bord pour le backlog.
- Désignez une équipe ou un 'propriétaire' individuel pour chaque catégorie de découverte (code, infra, cloud) avec des SLA documentés.
- Menez des "rétrospectives de pentest" régulières pour examiner les découvertes, les faux positifs et ajuster les outils.
Meilleures pratiques opérationnelles et de résilience en matière de sécurité du cloud
La sécurité du cloud ne se limite pas à la prévention ; elle exige également de se préparer aux perturbations et d'assurer la continuité des activités, c'est pourquoi l'excellence opérationnelle et les pratiques de résilience sont essentielles.
22. Établir des plans de réponse aux incidents
Vous vous souvenez du dicton cliché "Si vous ne planifiez pas, vous planifiez d'échouer" ; eh bien, il en va de même dans le monde de la sécurité.
Vous voyez, il ne s'agit pas de savoir si des incidents se produiront, car ils se produiront ; il s'agit de la façon dont vous réagissez lorsqu'ils surviennent et de ce que vous faites après coup.
Qu'est-ce qui constitue un plan de réponse aux incidents solide ?
- Vous devez définir clairement ce qui constitue un incident (violation de données, interruption de service due à un malware, etc.). Sans cela, il y a toujours de la confusion.
- Désignez qui fait quoi, qu'il s'agisse des développeurs, des leads techniques, de la communication ou du service juridique. Incluez également les contacts de secours.
- Internes et externes. Qui doit être informé ? Quand ? Et comment ?
- Établissez un flux étape par étape : détection → évaluation → confinement → éradication → récupération → leçons apprises. Incluez des critères définissant le niveau de gravité d'un incident avant son escalade (niveaux de gravité).
- Si les journaux doivent être conservés, les systèmes mis en quarantaine ou une aide externe est requise, le plan doit inclure la manière de préserver les preuves.
- Menez des exercices de simulation ou des ateliers de table au moins une fois par an pour parcourir le plan et identifier les lacunes.
23. Mettre en œuvre un modèle de sécurité Zero Trust
Jusqu'à présent, nous avons mentionné le Zero Trust à plusieurs reprises dans ce guide. Le Zero Trust n'est pas un produit que l'on achète ; c'est un état d'esprit : ne jamais faire confiance, toujours vérifier. Dans le cloud, où les réseaux sont plats et les identités constituent le nouveau périmètre, ce modèle est plus important que jamais.
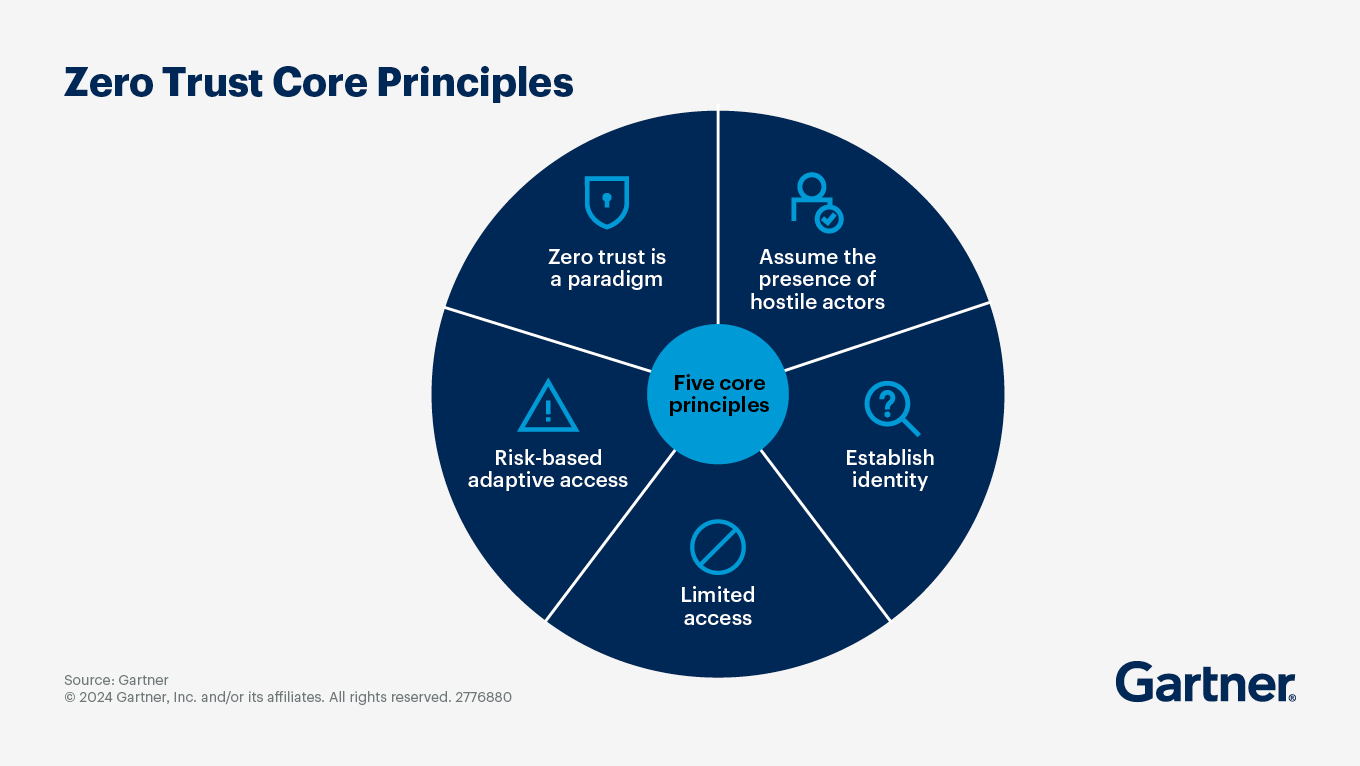
Au lieu de supposer que les utilisateurs ou les services au sein de votre environnement sont sûrs, le Zero Trust contraint chaque requête, humaine ou machine, à prouver son identité. Cela implique une authentification forte, une autorisation basée sur le principe du moindre privilège, des connexions chiffrées et une validation continue. Si un attaquant parvient à s'introduire, le Zero Trust l'empêche de se déplacer latéralement.
Bonnes pratiques à adopter :
- Exigez l'AMF et des contrôles d'identité robustes pour chaque utilisateur et chaque charge de travail.
- Appliquer le principe du moindre privilège avec des politiques RBAC/ABAC granulaires.
- Utilisez la micro-segmentation réseau et l'identité de service, tels que SPIFFE/SPIRE, pour vérifier le trafic machine-à-machine.
- Chiffrer tout le trafic avec TLS/mTLS, même à l'intérieur de VPC ou de clusters « de confiance ».
- Surveillez continuellement les comportements et révoquez les sessions si des anomalies apparaissent.
24. Tirer parti des Cloud Access Security Brokers (CASB)
L'organisation moyenne utilise une multitude d'applications SaaS, généralement pour de bonnes raisons. Lorsque l'on cherche à avancer rapidement, on ne veut pas consacrer de précieuses heures d'ingénierie à réinventer la roue. Le défi est que beaucoup d'entre elles sont adoptées sans supervision de la sécurité (shadow IT), créant ainsi des angles morts.
Un Cloud Access Security Broker (CASB) vous offre un point de contrôle centralisé : une visibilité sur les applications utilisées, les données qui y transitent et si l'utilisation est conforme aux politiques.
Les CASB appliquent des contrôles dans les environnements SaaS. Les mesures incluent la prévention du téléchargement de données sensibles vers des lecteurs personnels, l'exigence de chiffrement pour le partage de fichiers et le blocage des connexions provenant de lieux à risque. Ils agissent comme un « liant » de sécurité entre vos utilisateurs, les applications SaaS et les politiques IAM et DLP existantes.
Bonnes pratiques à adopter :
- Déployez un CASB en mode proxy ou API pour surveiller l'utilisation des SaaS au sein de votre organisation.
- Identifier le shadow IT en découvrant les applications non autorisées et en bloquant celles qui sont risquées.
- Appliquer des politiques DLP qui empêchent les données sensibles de quitter les applications autorisées.
- Exiger un accès sensible au contexte (état de l'appareil, géolocalisation, score de risque) avant d'accorder l'accès aux SaaS.
- Intégrez les CASB à votre SIEM/SOAR pour la détection d'incidents et la réponse automatisée.
25. Développez une forte culture de sensibilisation à la sécurité
Toutes les bonnes pratiques abordées dans cet article seront vaines si les personnes chargées de les mettre en œuvre et de les respecter les négligent. Le dicton « une chaîne n'est aussi solide que son maillon le plus faible » s'applique également aux individus de votre organisation.
Bien que vous ne souhaitiez pas ennuyer votre équipe avec des séminaires obligatoires qui consomment un temps précieux pouvant être consacré à l'atteinte de vos objectifs, vous devez également trouver un équilibre en évaluant constamment votre posture de sécurité et en vous assurant que vos équipes comprennent l'impact d'une conscience accrue de la sécurité.
Bonnes pratiques à adopter :
- Formation continue, simulations de phishing et récompense des comportements sécurisés.
- Intégrez la sécurité aux revues de code ; ne vous contentez pas de rechercher des bugs, mais aussi des secrets codés en dur, des appels d'API sur-privilégiés et des endpoints exposés.
- Gamifiez la sensibilisation à la sécurité en intégrant des classements pour ceux qui détectent le plus de vulnérabilités et des récompenses pour le signalement des problèmes de sécurité.
- Analyses post-incident sans blâme pour les incidents de sécurité. Si les gens sont licenciés pour des erreurs honnêtes, ils les cacheront mieux la prochaine fois.
- Les sessions de modélisation des menaces incitent les développeurs à penser comme des attaquants pendant la phase de conception, et non après le déploiement du code.
Adoptez le Shift Left, gardez une longueur d'avance, déployez en toute confiance
Cela dit, il est important de comprendre que la sécurité est davantage un parcours qu'une destination. Il y a quelques années à peine, si vous nous aviez dit chez Aikido que « vibe coding security » serait une expression utilisée dans la même phrase, vous auriez reçu des regards appuyés. Cependant, nous nous adaptons et prenons des mesures proactives pour vous éviter de faire la une des journaux pour une faille de sécurité.
C'est essentiellement la raison pour laquelle nous avons créé Aikido : pour vous aider à adopter le shift left, à détecter les mauvaises configurations tôt et à permettre à vos développeurs d'avancer rapidement sans compromettre la sécurité.
Votre question est peut-être maintenant : Alors, comment commencer ?
La réponse est que vous l'avez déjà fait. En lisant ces bonnes pratiques et en prenant des mesures pour renforcer la sécurité de votre cloud. L'étape suivante est simple : planifiez une démo avec notre équipe et découvrez comment Aikido peut vous décharger des tâches lourdes, afin que vous puissiez vous concentrer sur l'essentiel : livrer en toute confiance !
Lisez d'autres articles de notre série sur la sécurité du cloud :
Sécurité du cloud : Le guide complet
Sécurité des applications cloud : Sécuriser les applications SaaS et les applications cloud personnalisées
Outils et plateformes de sécurité du cloud : La comparaison 2025


