Les Tests de sécurité des applications statiques (SAST) analysent votre code source — et non l'application en cours d'exécution — pour détecter les schémas de codage non sécurisés avant qu'ils n'atteignent la production. C'est l'un des outils de sécurité les plus précoces et les plus efficaces que vous puissiez intégrer à un workflow de développement, car il détecte les erreurs au moment où elles sont les moins coûteuses à corriger : pendant que vous écrivez le code.
Ce que le SAST fait réellement
Le SAST analyse les fichiers source, recherchant des schémas qui indiquent une vulnérabilité : les entrées utilisateur non assainies utilisées dans les requêtes SQL, la cryptographie inappropriée, les flux d'authentification non sécurisés, et plus encore. Parce qu'il inspecte le code de manière statique (sans l'exécuter), le SAST excelle à signaler les pratiques de codage non sécurisées tôt dans le SDLC.
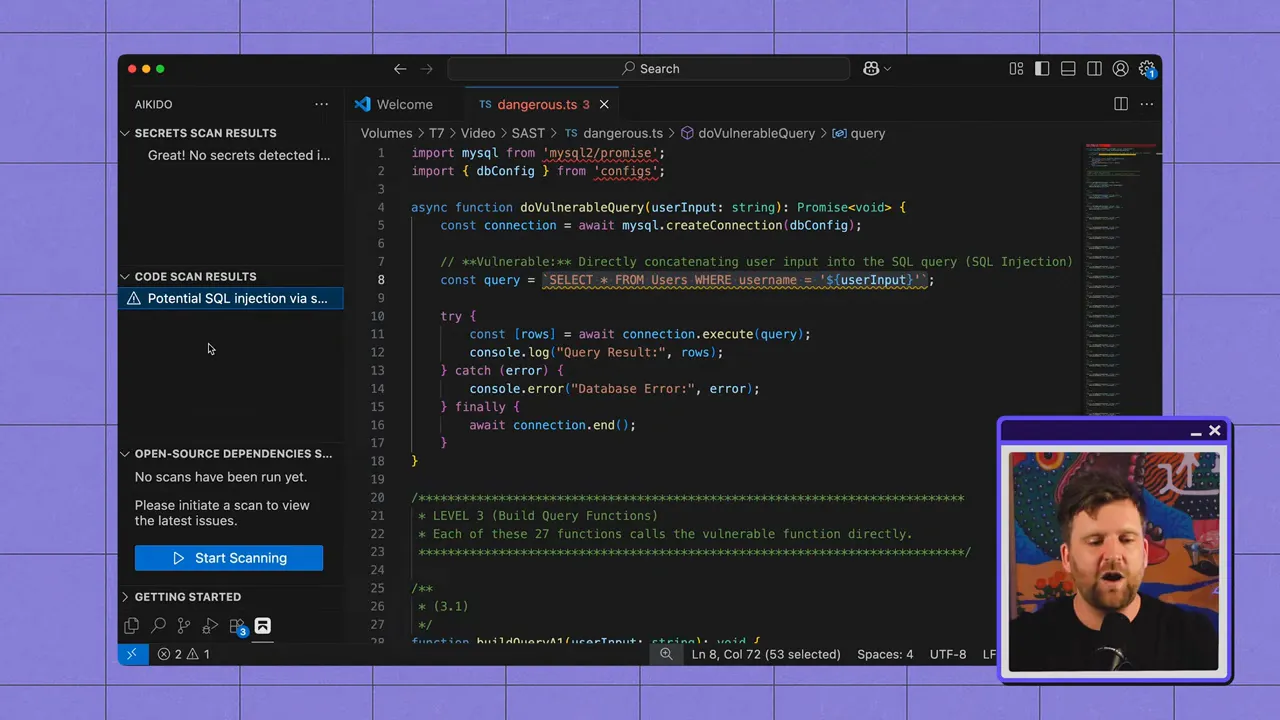
Là où le SAST excelle
- Détection précoce : S'exécute dans votre IDE ou pipeline CI, détectant les erreurs avant la mise en staging ou en production.
- Couverture basée sur des règles : Les schémas non sécurisés connus (par exemple, les sources/sinks d'injection SQL) peuvent être détectés de manière fiable avec des règles bien écrites.
- Feedback convivial pour les développeurs : Les intégrations peuvent faire remonter les problèmes en contexte afin que les ingénieurs puissent les corriger immédiatement.
Ses limites
- Contexte d'exécution limité : Le SAST ne peut pas facilement déterminer si un chemin de code est atteignable en production, ni comment la configuration d'exécution et les dépendances affectent le risque.
- Peu efficace pour les failles logiques : Les vulnérabilités de la logique métier et les problèmes d'autorisation complexes sont difficiles à détecter avec des règles purement statiques.
- Angles morts des dépendances et de l'environnement : Les vulnérabilités introduites à l'exécution ou via des packages externes échappent souvent à l'analyse statique.
Comment le SAST trouve les vulnérabilités : règles vs. IA
Les outils SAST traditionnels sont principalement basés sur des règles : un moteur analyse le code et applique des milliers de règles qui correspondent à des schémas non sécurisés connus. Cette approche est efficace et précise pour de nombreuses classes de failles, car les schémas sont bien compris.
« En ce qui concerne le code statique, nous connaissons réellement les schémas qui rendent le code vulnérable. »
Certains fournisseurs promeuvent la détection basée sur l'IA, mais l'analyse brute par LLM a tendance à être bruyante et coûteuse en calcul — la célèbre analogie s'applique : c'est comme tondre sa pelouse avec une Ferrari. Au lieu de cela, l'utilisation la plus efficace de l'IA jusqu'à présent n'est pas l'analyse en soi, mais l'ajout de contexte à l'échelle du projet pour améliorer le triage et les suggestions de correctifs.
Le SAST open source en pratique : OpenGrep (un fork de Semgrep)
Les outils SAST open source sont d'excellents points de départ car ils séparent le moteur d'analyse de l'ensemble de règles. Le moteur effectue l'analyse syntaxique et la correspondance ; les règles, souvent maintenues par la communauté, définissent ce qui est considéré comme « mauvais ».
Avec un modèle moteur-plus-règles, vous pouvez :
- Inspecter et personnaliser les règles pour votre base de code.
- Écrire des règles spécifiques au projet pour des schémas uniques que les ensembles de règles commerciaux ne détectent pas.
- Partager des règles personnalisées utiles avec la communauté afin que votre équipe et d'autres en bénéficient.
Pourquoi les faux positifs sont devenus un problème de réputation
Le SAST basé sur des règles ratisse souvent large. C'est bon pour la détection — vous trouvez plus de problèmes potentiels — mais cela génère aussi beaucoup de bruit. De nombreux problèmes signalés ne sont pas atteignables en production ou sont sûrs dans un contexte de projet particulier, de sorte que les équipes passent du temps à enquêter sur des alertes sans importance.
Imaginez l'ancien SAST comme une pêche au grand filet : vous attraperez du poisson, mais aussi beaucoup de déchets. Quelqu'un doit tout trier pour trouver ce qui a de la valeur.
Où l'IA aide réellement le SAST : triage automatique et correction automatique
Plutôt que de remplacer l'analyse basée sur des règles, les outils SAST modernes combinent des règles statiques avec des couches alimentées par l'IA qui ajoutent du contexte et réduisent le bruit :
- Triage automatique par IA : Les modèles d'IA consomment les résultats SAST et le contexte du projet pour estimer l'atteignabilité et l'impact réel. Ils priorisent les découvertes que les développeurs doivent réellement corriger en premier (orientées production, chemins atteignables, problèmes à fort impact).
- Arbres d'appels et atteignabilité : L'IA peut construire un arbre d'appels pour une fonction signalée et montrer d'où proviennent les entrées et comment les données circulent dans le dépôt, facilitant ainsi la détermination de l'exploitabilité d'un problème.
- Suggestions de correctifs automatiques : L'IA peut proposer des correctifs de code concis et exploitables (par exemple, des requêtes paramétrées au lieu de SQL concaténé par chaîne), ce qui accélère la remédiation au sein de l'IDE.

Où exécuter le SAST dans votre flux de développement
Pour maximiser la valeur, exécutez le SAST à plusieurs étapes du SDLC :
- Dans l'IDE : Les plugins IDE détectent les problèmes au fur et à mesure que les développeurs tapent, permettant des corrections immédiates et l'apprentissage.
- Dans le dépôt distant : Les analyses sur le dépôt fournissent une source unique de vérité pour ce qui sera livré. Ceci est essentiel si une analyse IDE a été manquée ou mal configurée.
- Dans les pipelines CI/CD : Les analyses automatisées pendant les builds appliquent les portes de politique et empêchent le code non sécurisé de passer en staging ou en production.

Recommandations pratiques pour les équipes
- Commencez par l'open source : Utilisez un outil communautaire pour découvrir ce que le SAST trouve dans votre base de code et gagnez en confiance avant d'acheter des outils commerciaux.
- Personnalisez les règles : Ajoutez des règles spécifiques au projet pour les modèles uniques à votre stack ; partagez les règles utiles avec la communauté.
- Intégrez l'IA là où elle est utile : Adoptez le triage assisté par l'IA pour réduire le bruit et la correction automatique pour accélérer la remédiation — mais ne vous fiez pas aux LLM pour l'analyse brute à grande échelle aujourd'hui.
- Intégrez à trois points : l'IDE pour l'immédiateté du développeur, le dépôt comme source de vérité, la CI pour l'application des politiques.
- Mesurez et ajustez : Suivez le rapport signal/bruit, ajustez les seuils et itérez sur les règles et les modèles de triage afin que votre équipe fasse confiance au scanner.
Points clés à retenir
Le SAST reste l'un des moyens les plus rentables de réduire les risques de sécurité, car il détecte les problèmes au niveau du code dès les premières étapes. Les moteurs basés sur des règles demeurent les outils essentiels pour la détection, tandis que l'IA s'avère très précieuse en tant que couche contextuelle qui priorise les résultats, explique la joignabilité et propose des correctifs.
Commencez modestement avec le SAST open source pour découvrir les problèmes présents dans votre code. Lorsque le bruit ou l'échelle devient un problème, ajoutez le triage assisté par l'IA et l'autocorrection pour parvenir à une véritable remédiation des vulnérabilités — plus rapidement et avec moins de friction pour les développeurs. Essayez Aikido Security dès aujourd'hui !


