Les secrets — clés API, mots de passe, certificats — sont l'équivalent numérique des confidences : ils sont destinés à un destinataire de confiance, pas au public. Dans les logiciels modernes, les secrets sont utilisés de manière programmatique, ce qui les rend à la fois omniprésents et fragiles. Laissés sans surveillance, ils sont fréquemment le point de départ de violations majeures. Ce guide explique où les secrets fuient, pourquoi leur détection est plus difficile qu'il n'y paraît, ce qu'une bonne détection apporte réellement et comment la déployer pour arrêter les fuites accidentelles avant qu'elles ne deviennent des incidents.
Qu'est-ce qui constitue un « secret » dans un logiciel ?
Un secret est tout identifiant qui donne accès à des systèmes ou des services : clés API, mots de passe de base de données, jetons OAuth, clés SSH, certificats TLS, et autres. Parce que les secrets sont consommés de manière programmatique, ils transitent par le code source, les pipelines CI, les machines des développeurs et les sauvegardes — créant ainsi une vaste surface d'attaque.
Comment les secrets fuient généralement
L'un des vecteurs de fuite les plus courants est l'historique du contrôle de version. Le scénario typique :
- Un développeur crée une branche de fonctionnalité et code en dur un identifiant pour tester rapidement quelque chose.
- Une fois vérifié, il remplace l'identifiant par une variable d'environnement ou un appel à un coffre-fort et pousse les modifications pour révision.
- Le code review ne regarde que le diff actuel ; le secret temporaire reste enfoui dans l'historique de la branche ou des commits.
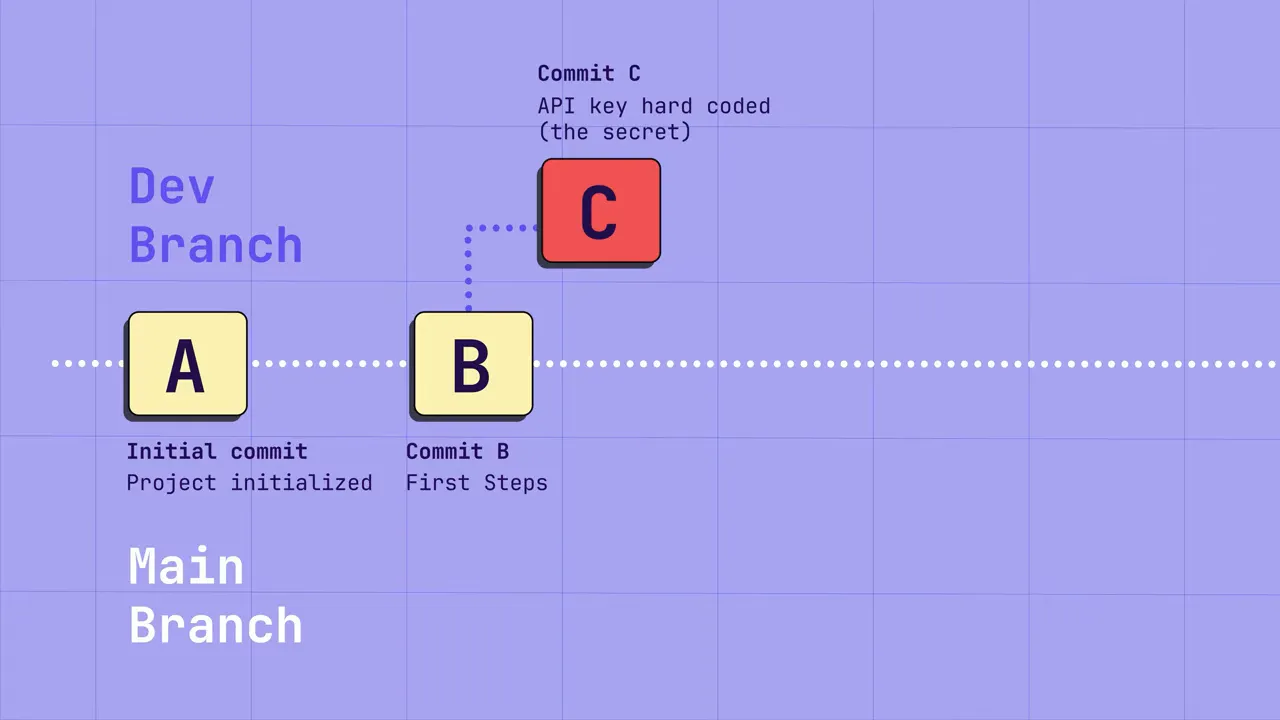
À moins de réécrire l'historique Git (ce qui est perturbateur et risqué), ce secret perdure. Si un attaquant accède à votre dépôt — même privé — il peut analyser l'historique et collecter des identifiants pour pivoter vers des cibles de plus grande valeur.
Quelle est l'ampleur du problème ?
Les recherches publiques montrent que ce problème est loin d'être rare. Des analyses à grande échelle de GitHub révèlent des millions de secrets exposés et une prévalence étonnamment élevée même dans les dépôts privés. De véritables violations prouvent le risque : des dumps de code source divulgués ont révélé des milliers d'identifiants, y compris des jetons cloud et des clés de paiement.

Pourquoi le SAST seul ne suffit pas
Les Tests de sécurité des applications statiques (SAST) sont efficaces pour détecter des vulnérabilités comme l'injection SQL ou la traversée de répertoires dans la base de code actuelle, mais ils analysent généralement le dernier instantané, et non l'intégralité de l'historique des commits. Les secrets sont différents : un secret présent dans n'importe quel commit, branche ou tag représente un risque de compromission. Cela signifie que la détection doit prendre en compte l'historique complet et les multiples dépôts où cet historique réside.
Pourquoi la détection de secrets est plus difficile qu'une simple « regex »
À première vue, on pourrait penser : écrire une regex pour « API_KEY= » et le tour est joué. En réalité, la détection de secrets doit équilibrer la précision et le rappel afin de ne pas submerger les développeurs de bruit :
- Les chaînes à forte entropie (valeurs d'apparence aléatoire) sont souvent des secrets — mais pas toujours. De nombreux artefacts non secrets présentent également une forte entropie.
- Les placeholders et les exemples émaillent les bases de code. Signaler naïvement chaque clé d'apparence suspecte déclenche des faux positifs qui perturbent les workflows.
- Les modèles de fournisseurs varient. Certains services (Stripe, AWS, Twilio) utilisent des préfixes ou des formats identifiables ; d'autres non.

À quoi ressemble une bonne détection de secrets
Une solution efficace de détection de secrets utilise plusieurs signaux pour réduire les faux positifs et détecter les fuites réelles :
- Correspondance de motifs pour les fournisseurs connus. Identifier les clés qui suivent des formats spécifiques aux fournisseurs (par exemple, les préfixes Stripe, les formes de jetons AWS).
- Validation lorsque possible. Tenter une validation non destructive (cette clé AWS existe-t-elle ? est-elle active ?) pour confirmer si une détection est réelle.
- Entropie + contexte. Utiliser des mesures d'entropie pour trouver des chaînes à forte aléatoire, puis inspecter le code environnant (chemin de fichier, noms de variables, commentaires) pour décider s'il s'agit d'un secret.
- Vérifications anti-dictionnaire. Filtrer les chaînes contenant des mots anglais ou des placeholders évidents pour réduire le bruit.
- Analyse tenant compte de l'historique. Analyser l'intégralité de l'historique Git à travers les branches, les tags et les miroirs — et pas seulement la pointe de la branche main.
- Déploiement centré sur le développeur. Exécuter la détection à la fois à distance (dépôts centraux) et localement (hooks de pré-commit, plugins d'IDE) pour stopper les fuites plus tôt dans le workflow.

Tester un outil de détection de secrets (et le piège courant)
Lors de l'évaluation des outils, les équipes effectuent souvent un test simple : elles codent en dur des chaînes d'apparence secrète évidentes et s'attendent à ce que le scanner les détecte. Ironiquement, un outil qui signale chaque faux secret évident peut être de mauvaise qualité — ce sont les outils bruyants qui semblent les meilleurs lors de tests naïfs.
Les bons outils ignorent intentionnellement les motifs triviaux et non réels ainsi que les valeurs de placeholder. Ils privilégient la validation des détections suspectes plutôt que d'alerter sur chaque chaîne aléatoire.
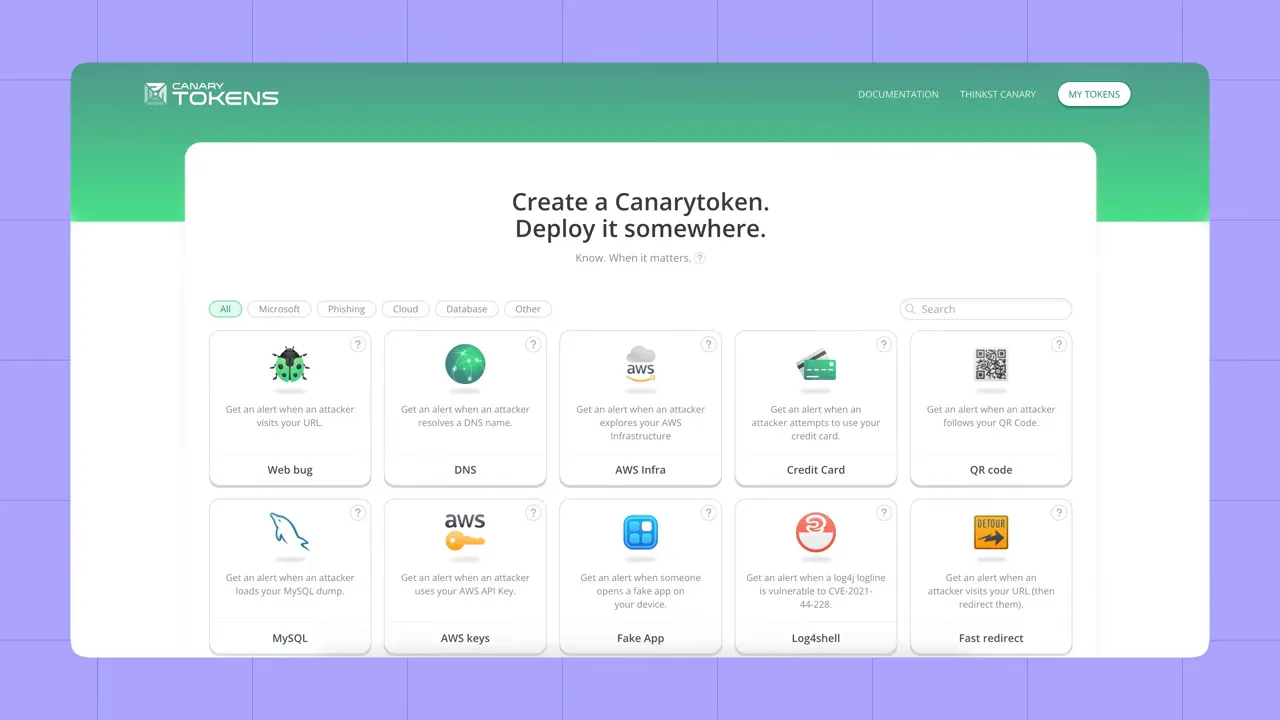
Comment tester correctement :
- Utilisez des honeytokens / canary tokens — de véritables clés API à faible risque que vous contrôlez — que vous pouvez publier en toute sécurité pour tester la détection et les alertes.
- Exécutez l'outil sur des branches historiques et des commits oubliés, et pas seulement sur de nouvelles fausses clés dans les fichiers actuels.
- Mesurez le taux de faux positifs et le succès de la validation : l'outil peut-il réduire le bruit tout en révélant des secrets réels et exploitables ?
Où déployer la détection de secrets
La détection doit être effectuée à plusieurs niveaux :
- Dépôts Git distants (obligatoire). Votre hébergement Git central est la source de vérité canonique : scannez tous les dépôts et l'historique complet. Tout secret présent ici doit être considéré comme compromis.
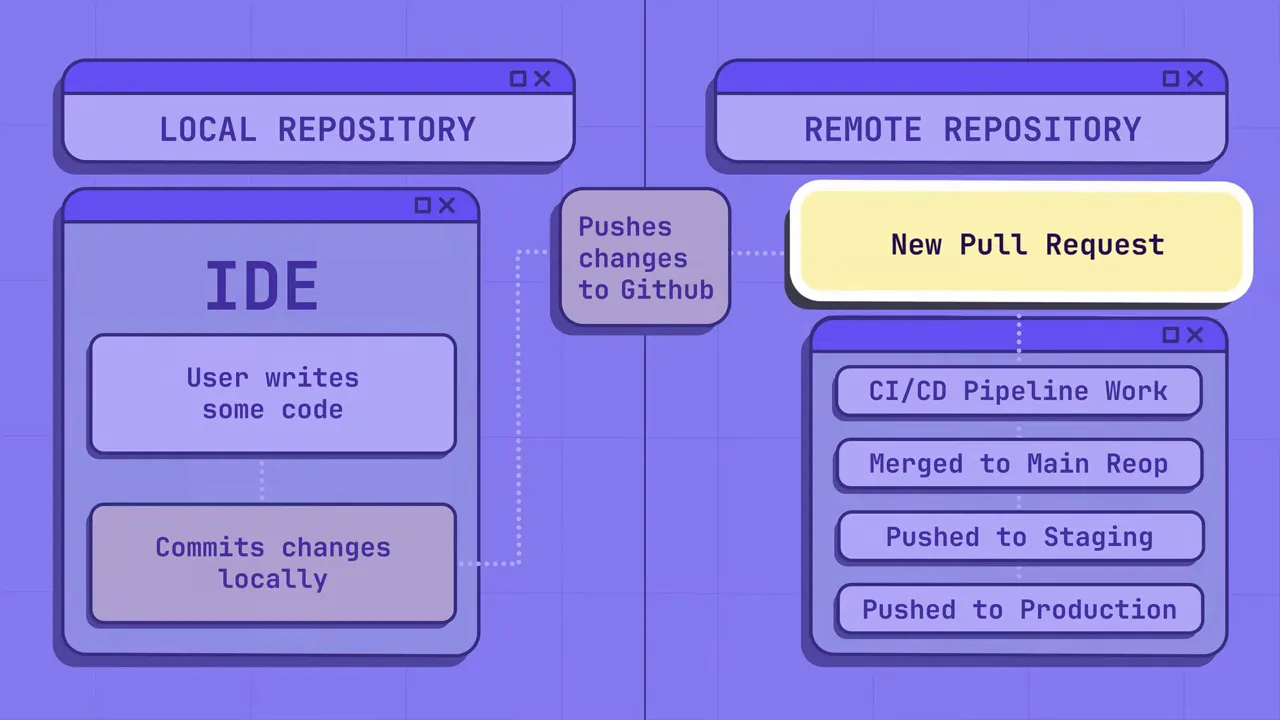
- Environnement local du développeur (fortement recommandé). Utilisez des hooks de pré-commit et des extensions d'IDE ou d'éditeur pour intercepter les secrets avant qu'ils n'atteignent un push. Le feedback local évite le remaniement et donne le contrôle aux développeurs.
- Pipelines CI/CD. Ajoutez des vérifications pour bloquer les fusions ou les déploiements lorsqu'un secret validé est trouvé, tout en veillant à ce que les règles minimisent les faux positifs qui bloquent le développement.
« Si un secret parvient à [votre dépôt distant], vous devez le considérer comme compromis. »
Checklist de remédiation rapide lorsque vous trouvez un secret divulgué
- Renouvelez le secret immédiatement (renouvelez les identifiants, révoquez les jetons).
- Évaluez la portée : quels systèmes étaient accessibles avec la clé ?
- Supprimez le secret de tous les commits et branches — envisagez de réécrire l'historique uniquement lorsque cela est nécessaire et acceptable pour votre workflow.
- Auditez les fuites similaires dans d'autres dépôts ou sauvegardes.
- Améliorez les workflows des développeurs et l'outillage pour éviter les récidives (plugins IDE, hooks de pré-commit, adoption de coffres-forts).
Récapitulatif : l'essentiel
- Les secrets sont omniprésents dans le développement moderne et résident souvent dans l'historique Git.
- Les outils SAST qui ne scannent que la tête de l'arbre ne sont pas suffisants pour la détection de secrets.
- Une bonne détection combine des modèles de fournisseurs, la validation, l'analyse d'entropie/de contexte et des filtres anti-dictionnaire pour réduire le bruit.
- Déployez la détection à la fois de manière centralisée (dépôts distants) et localement (IDE/hooks) pour détecter les fuites précocement et éviter un jeu du chat et de la souris.
- Testez les scanners de manière responsable en utilisant des honeytokens et des scans historiques plutôt que de simples fausses clés.
La détection de secrets est un problème continu et prioritaire pour les développeurs. Avec la bonne combinaison de signaux et de positionnement, vous pouvez réduire considérablement les risques sans submerger les développeurs de fausses alertes. Commencez par analyser votre historique git, ajoutez des protections locales et faites de la validation une fonctionnalité essentielle de toute solution de détection de secrets que vous choisissez. Essayez Aikido Security dès aujourd'hui !


