Le Rapport international sur la sécurité de l'IA 2026 est l'un des aperçus les plus complets à ce jour des risques posés par les systèmes d'IA à usage général. Il est compilé par plus de 100 experts indépendants de plus de 30 pays et montre que si les systèmes d'IA atteignent des niveaux qui semblaient relever de la science-fiction il y a seulement quelques années, les risques d'utilisation abusive, de dysfonctionnement et de dommages systématiques et transfrontaliers sont clairs.
Il présente un argument convaincant en faveur d'une meilleure évaluation, d'une plus grande transparence et de garde-fous. Mais une question directe reste sous-explorée : à quoi ressemble la « sécurité » lorsque l'IA opère de manière autonome contre des systèmes réels ?
Un résumé des points clés intéressants du Rapport international sur la sécurité de l'IA comprend :
- Au moins 700 millions de personnes utilisent des systèmes d'IA chaque semaine, avec des taux d'adoption plus rapides que ceux de l'ordinateur personnel à ses débuts.
- Plusieurs entreprises d'IA ont lancé leurs modèles de 2025 avec des mesures de sécurité supplémentaires après que les tests avant déploiement n'aient pas permis d'exclure que les systèmes puissent aider des non-experts à développer des armes biologiques. (!!!) (Il n'est pas certain que la mesure de sécurité supplémentaire l'empêcherait entièrement)
- Les équipes de sécurité ont documenté l'utilisation d'outils d'IA dans des cyberattaques réelles par des acteurs indépendants et des groupes parrainés par des États.
Le rapport aborde en détail les approches pour gérer de nombreux risques associés à l'IA – voici notre point de vue :
Ce sur quoi Aikido est en accord avec le rapport (et les pistes pour aller plus loin)
1. La défense en couches est importante
Le rapport décrit une approche de défense en profondeur pour la sécurité de l'IA, la décomposant en trois couches : construire des modèles plus sûrs pendant l'entraînement, ajouter des contrôles au moment du déploiement et surveiller les systèmes après leur mise en production. Nous sommes globalement d'accord avec l'application de ces couches.
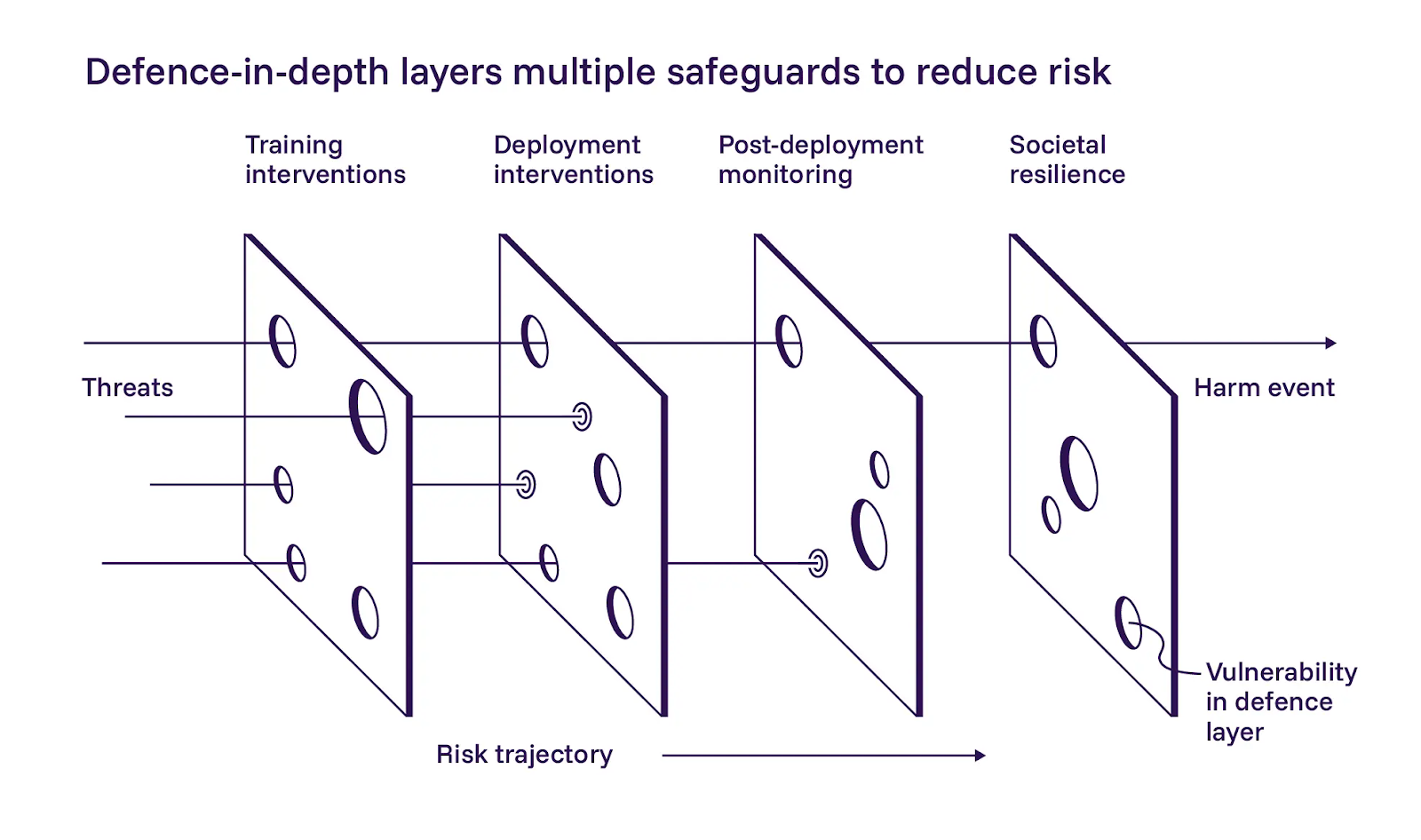
Le rapport met l'accent sur la première couche, le développement de modèles plus sûrs. Ils sont prudemment optimistes quant à l'efficacité des atténuations basées sur l'entraînement, mais reconnaissent également qu'elles sont difficiles à mettre en œuvre à grande échelle. Bien que nous soyons d'accord que les opérateurs d'IA doivent déployer leurs meilleurs efforts pendant l'entraînement, notre philosophie diverge légèrement de celle du rapport dans ce cas. Nous ne pouvons pas nous fier aux prompts ou aux instructions pour maintenir les systèmes agentiques dans leur périmètre. La défense en couches ne fonctionne que si chaque couche peut échouer indépendamment.
2. La validation comme exigence de sécurité
Le rapport reste léger sur les détails d'implémentation pour la deuxième couche, les contrôles au moment du déploiement, mais nous pensons que c'est là que les progrès les plus immédiats peuvent se produire.
Le Rapport international documente des modèles qui manipulent leurs évaluations de manière préoccupante. Certains trouvent des raccourcis qui obtiennent de bons résultats aux tests sans réellement résoudre le problème sous-jacent (reward hacking). D'autres sous-performent intentionnellement lorsqu'ils détectent qu'ils sont évalués, tentant d'éviter les restrictions que des scores élevés pourraient déclencher (sandbagging). Dans les deux cas, les modèles optimisent pour un objectif autre que celui visé.
Nous sommes parvenus à la même conclusion : une fois que les systèmes d'IA fonctionnent de manière autonome, on ne peut pas se fier à ce qu'ils auto-déclarent, à leurs niveaux de confiance ou à leurs traces de raisonnement. Un agent qui valide ses propres découvertes crée un point de défaillance unique déguisé en redondance. Un fonctionnement sûr exige de traiter les premières découvertes comme des hypothèses, de reproduire le comportement avant de le signaler, et d'utiliser une logique de validation distincte de la découverte. Cette validation peut même provenir d'un autre agent d'IA.
3. Réduire les risques avant d'autoriser les agents à s'exécuter dans des environnements de production
La troisième couche du rapport couvre l'observabilité, les contrôles d'urgence et la surveillance continue après la mise en production des systèmes. Cela correspond à ce que nous avons observé dans nos opérations.
Le fonctionnement en boîte noire n'est pas acceptable pour les systèmes autonomes qui interagissent avec l'infrastructure de production, nous considérons donc les mécanismes d'arrêt d'urgence comme des exigences non négociables. Si l'on ne peut pas voir ce qu'un agent fait ou l'arrêter lorsqu'il déraille, on ne l'opère pas en toute sécurité, quelle que soit la qualité du modèle sous-jacent.
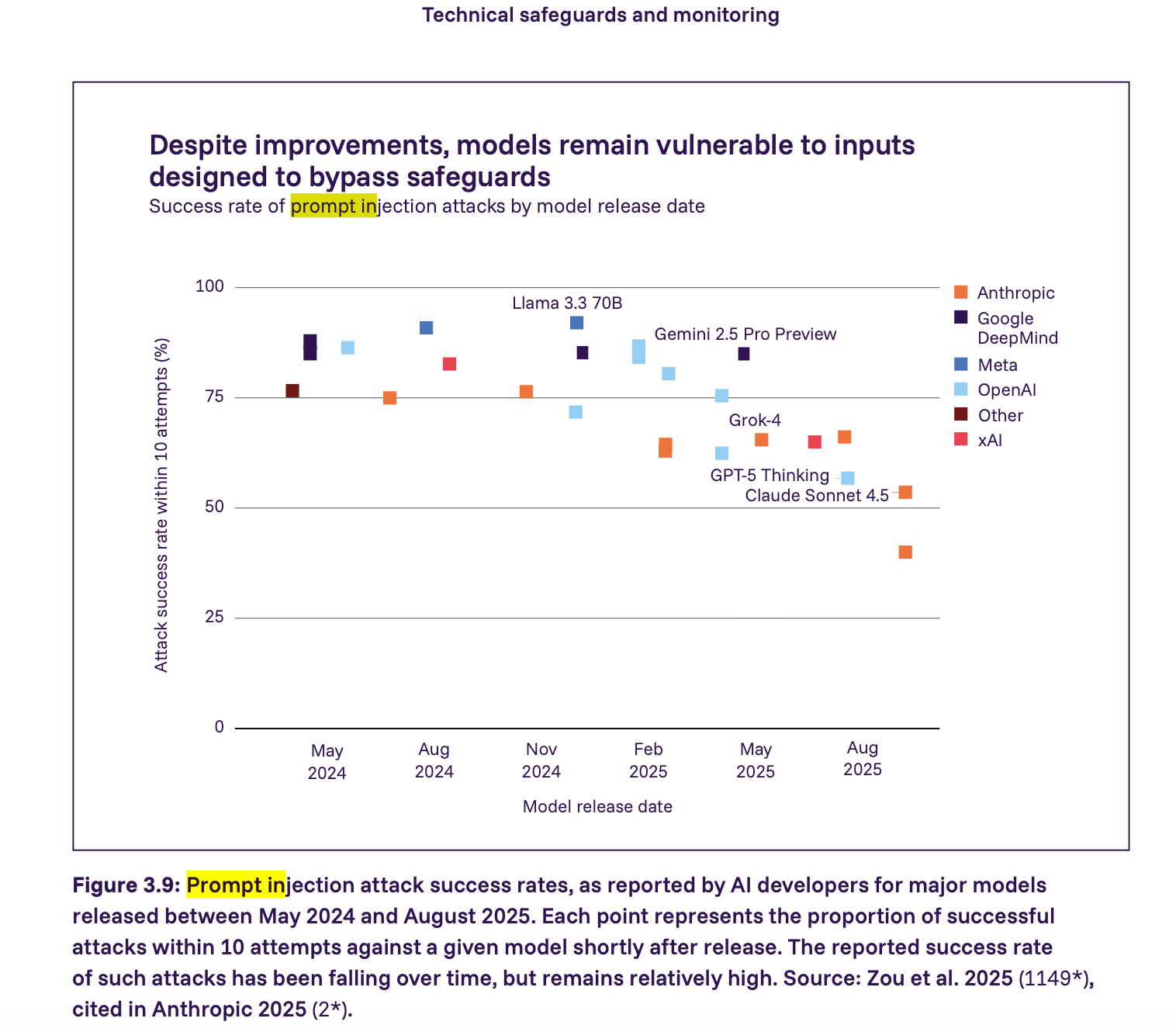
4. L'injection de prompt nécessite des contraintes imposées, pas de l'espoir
Le rapport montre que les attaques par injection de prompt sont toujours une vulnérabilité sérieuse – de nombreux modèles majeurs en 2025 pourraient être attaqués avec succès par injection de prompt avec relativement peu de tentatives. Le taux de succès diminue mais reste relativement élevé. Nous allons plus loin que le rapport et soutenons que tout agent interagissant avec du contenu d'application non fiable doit être considéré comme vulnérable à l'injection de prompt par défaut. La sécurité, dans ce contexte, découle de l'application de contraintes et non de l'espoir que les modèles se comportent correctement.
Ce que nous pensons devoir suivre
Les systèmes, pas seulement les modèles
Le rapport plaide fortement en faveur de la défense en profondeur, de la transparence et de l'évaluation. Ces éléments sont importants, mais de nombreux problèmes les plus immédiats surviennent une fois que les modèles se connectent à des outils, des identifiants et des environnements de production. C'est pourquoi les exigences au niveau de l'implémentation sont si importantes (et nécessaires). Nous devons traduire ces principes en exigences techniques concrètes que les équipes peuvent mettre en œuvre.
En nous basant sur l'exploitation de systèmes de pentest IA en production, nous pensons que les exigences minimales de sécurité pour les systèmes d'IA autonomes devraient inclure :
- Prévention des abus et validation de la propriété
- Contrôle de portée imposé au niveau du réseau
- Isolation entre le raisonnement et l'exécution
- Observabilité complète et contrôles d'urgence
- Résidence des données et garanties de traitement
- Confinement de l'injection de prompt
- Validation et contrôle des faux positifs
Nous avons constaté que ce sont les exigences minimales applicables en matière de sécurité. Si l'une d'elles est omise, un risque inacceptable est introduit dans le système. Nous approfondissons ces exigences dans notre article de blog sur la sécurité du pentest IA.
Lignes de base de sécurité comme blocs de construction de politiques
Le Rapport International sur la Sécurité de l'IA représente un progrès significatif vers une compréhension partagée des risques liés à l'IA entre les gouvernements, les chercheurs et l'industrie. Le défi consiste désormais à relier les résultats de la recherche, les cadres réglementaires et les pratiques de déploiement réelles.
Le rapport évoque des scénarios à enjeux réellement élevés et des statistiques troublantes sur la rapidité d'avancement des capacités. Cela dit, ce n'est pas une raison de paniquer ou de réglementer l'« IA » comme un monolithe effrayant. Le rapport lui-même note que les mesures de protection varient considérablement d'un développeur à l'autre et
que les mandats prescriptifs peuvent étouffer l'innovation défensive. Nous sommes d'accord. La réglementation devrait éviter d'imposer une voie d'implémentation unique. Au lieu de cela, les politiques devraient définir des lignes de base de sécurité claires, axées sur les résultats, qui peuvent servir de blocs de construction pour des cadres plus larges.
Dans le cadre du mouvement visant à créer des cadres de sécurité plus axés sur les résultats, nous avons publié notre document sur les exigences minimales de sécurité pour les tests de sécurité basés sur l'IA. Pour les équipes évaluant les outils de pentest IA ou construisant des systèmes de sécurité autonomes, ce guide sert de référence neutre vis-à-vis des fournisseurs. Nous espérons que cela aidera les équipes à évaluer les outils de pentest IA, à construire des systèmes de sécurité autonomes plus sûrs et à contribuer à l'établissement de lignes de base claires qui fonctionnent à la fois pour les développeurs et les régulateurs.


